Фонетический разбор слова — план, примеры
Как правильно сделать фонетический разбор слова?
Фонетический разбор – это характеристика структуры слогов и состава слова из звуков.
Памятка
План фонетического разбора
- Записать слово орфографически правильно.
- Разделить слово на слоги и найти место ударения.
- Отметить возможности переноса слова по слогам.
- Фонетическая транскрипция слова.
- По порядку характеризовать все звуки: а. согласный – звонкий – глухой (парный или непарный), твёрдый или мягкий, какой буквой он обозначен; б. гласный: ударный или безударный.
- Подсчитать количество букв и звуков.
- Отметить случаи, если звук не соответствует букве.
Образцы фонетического разбора слов:
Я очень люблю есть морковь.
Фонетический разбор слова люблю:
- люблю
- люб – лЮ (на второй слог падает ударение, 2 слога)
- люб-лю
- [л’убл’у]
- Л – [л’] согласный, мягкий, звонкий и непарный;
Ю – [у] – гласный и безударный;
Б – [б] – согласный, твердый, звонкий и парный
Л – [л’] – согласный, мягкий, звонкий и непарный;
Ю – [у] – гласный и ударный - В слове 5 букв и 5 звуков.


https://uchim.org/russkij-yazyk/foneticheskij-razbor-slova — uchim.org
Фонетический разбор слова морковь:
- морковь
- мор-кОвь (на второй слог падает ударение, 2 слога).
- Перенос: мор-ковь
- [маркоф’]
- М – [м] – согласный, твердый, звонкий и непарный.
О – [а] – гласный и безударный.
Р – [р] – согласный, твердый, звонкий и непарный.
К – [к] – согласный, твердый, глухой и парный.
О – [о] – гласный и ударный.
В – [ф’] – согласный, мягкий, глухой и парный.
Ь —————————– - В слове 7 букв и 6 звуков.
- о – а, в – глухой звук ф, ь смягчает в.
Видео про фонетическую транскрипцию
Полезные советы:
- Делая фонетический разбор, нужно произнести слово вслух.
- Важно всегда проверять транскрипцию.
- Обязательно обращать внимание на орфограммы при фонетическом анализе.
- Также обращать внимание на звуки, которые произносятся в слабых позициях, таких как: стечение согласных или стечение гласных, согласные шипящие, непарные согласные по твёрдости и мягкости или звонкости и глухости.

Возможно, вам также понадобится Морфологический разбор.
Всё для учебы » Русский язык » Фонетический разбор слова — план, примеры
Фонетический (звуко-буквенный) разбор слова, транскрипция. Онлайн сервис
{{ info }}
ВыполнитьТекстовод.Фонетика производит фонетический разбор слова онлайн.
Добавьте слово в форму, и программа автоматически произведёт его разбор.
Такой разбор еще называют звуко-буквенный — т.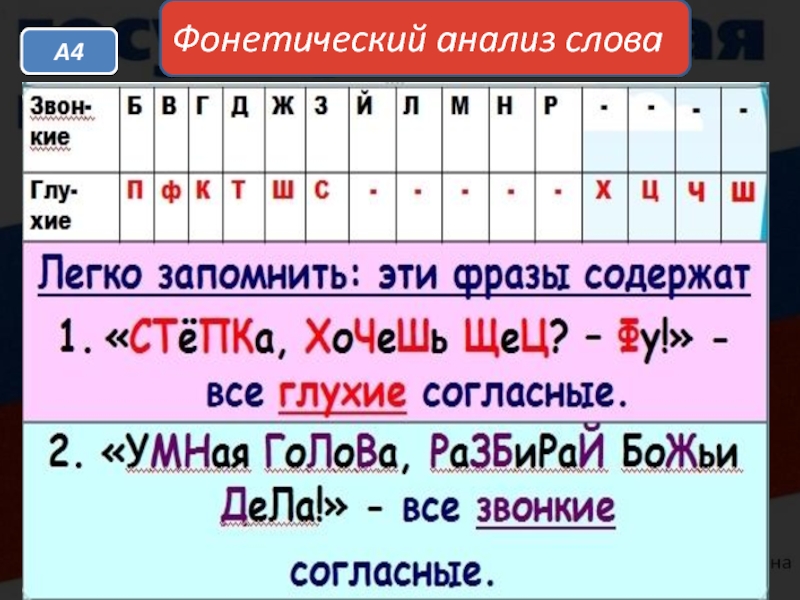 к. в процессе анализа слова подсчитывается количество букв и звуков.
к. в процессе анализа слова подсчитывается количество букв и звуков.
Также, при фонетическом разборе слово делится на слоги и ставится ударение.
Но основная цель — выполнить фонетическую транскрипцию и произвести характеристику всех звуков.
Порядок проведения фонетического разбора:
1. Постановка ударения.
2. Разбивка на слоги.
Здесь предоставляются 2 варианта: слоги для анализа и варианты для переноса слова.
3. Транскрипция слова [в квадратных скобках].
4. Характеристика слова.
5. Транскрипция каждого звука по порядку.
Звук помещается в квадратные скобки.
а) Если он согласный, то определяются следующие его характеристики:
- звонкий/глухой/сонорный,
- парный/непарный,
- твёрдый/мягкий.
Мягкость звука обозначается знаком апострофа [«].
б) Если звук гласный, то устанавливается его ударность.
в) Если у буквы отсутствует звук (ь, ъ и др.), то ставится прочерк [-].
Заметка.
* Не бывает звуков [е], [ё], [ю], [я]. Буквы е, ё, ю, я имеют в разных словах различные звуки.
Пример.
* Также, нет звука у непроизносимых согласных в корне слова.
Например, солнце — [сонц»э]
6. Подсчёт букв и звуков.
7. Составление цветовой схемы слова.
Наш сервис позволяет сделать звуко-буквенный разбор слова русского языка любой части речи.
В качестве бонуса программа определяет часть речи, число, падеж, категории одушевленности и переходности, род, лицо, время; вид, наклонение, степень и форму (глаголов) и др.
Помните, что е и ё — это две разные буквы, влияющие на результат разбора.
Примите, также, во внимание, что омографы (слова с одинаковым написанием, но разным произношением) будут иметь совершенно разный фонетический разбор.
На сайте textovod.com вы найдёте разбор всех возможных омографов.
Учтите, что последовательность нашего разбора может отличаться от порядка анализа вашей учебной программы.

Фонетический разбор слова. Начальная школа.
Фонетика – раздел науки о языке, в котором изучаются звуки речи.
Буквы – это графические знаки, с помощью которых звуки речи обозначаются при письме.
Звуки мы произносим и слышим, буквы – видим и пишем. Читая слова, мы видим буквы, а произносим звуки.
Звуки бывают гласные и согласные.
Гласные звуки.
При произнесении гласных выдыхаемый воздух свободно выходит изо рта и не встречает преград. Гласные звуки можно петь. Они состоят только из голоса, который образуется при дрожании голосовых связок.
В русском языке 10 гласных букв: А-Я,О-Ё, У-Ю, Ы-И, Э-Е,
но 6 гласных звуков: [А], [О], [У], [Ы], [ Э], [И].
- А, О, У, Ы, Э – это буквы, которые дают предыдущему согласному команду: «Читайся твёрдо!», но звуки [ч’], [щ’] – всегда мягкие:
сон [сон], дым [дым], чаща [ч’ащ’а], часы [ч’асы].
- Я, Ё, Ю, И, Е – это буквы, которые дают предыдущему согласному команду: «Читайся мягко!» (обозначают мягкость предыдущего согласного), но звуки [ж], [ш], [ц] остаются всегда твердыми:
мята [м’ата], тёрка [т’орка], мюсли [м’усл‘и], мел [м’эл], лес [л’эс], жир [жыр], ширь [шыр’], цифра [цыфра].
- Буквы Я, Ё, Ю, Е – йотированные. Они могут давать один или два звука, в зависимости от положения в слове.
- Я, Ё, Ю, Е стоят после согласных, то обозначают мягкость предыдущего согласного (кроме всегда твердых [ж], [ш], [ц]) и дают один гласный звук : я – [а], ё – [о], ю – [у], е – [э] :
Мяч[м‘ач], тёрн [т‘орн], тюль [т‘ул’], пена [п‘эна]. - Я, Ё, Ю, Е дают два звука: согласный [й’] и соответствующий гласный, если они стоят
- в начале слова: яма [й’aма ], ёлка [й’олка], юла [й’у ла ], ель [й’э л’];
- после гласных: маяк [май’ак], поёт [пай’от], пою т [пай’ут], поел [пай’эл];
- после разделительных Ъ и Ь знаков: деревья [д’ир’эв’й’а ], объём [абй’ом], вьюга [вй’уга], съезд [сй’эст].
- Я, Ё, Ю, Е стоят после согласных, то обозначают мягкость предыдущего согласного (кроме всегда твердых [ж], [ш], [ц]) и дают один гласный звук : я – [а], ё – [о], ю – [у], е – [э] :


- В транскрипции буквы Я, Ё, Ю, Е не используются. Звуков [е], [ё], [ю], [я] не существует.
- Буква И после Ь обозначает два звука: чьи [ч’й’и], лисьи [лис’й’и]
- [й’] – согласный, всегда звонкий, всегда мягкий звук .
В состав слога обязательно входит гласный звук: “Сколько в слове гласных, столько и слогов. Это знает каждый из учеников!”
Для малышей! Чтобы определить количество слогов в слове, надо приложить раскрытую ладошку под подбородок и четко произнести слово. На гласных подбородок ударит по ладошке. Посчитайте количество таких ударов и узнаете количество слогов.
Согласные звуки.
При произнесении согласных выдыхаемый воздух встречает преграды (губы, зубы и язык) в ротовой полости. Всего 36 согласных звуков.
Согласные звуки бывают твердые и мягкие, звонкие и глухие.
- Звонкие
- образуются при помощи голоса (вибрируют голосовые связки) и шума.
- Л, М, Н, Р, Й – самые звонкие согласные (больше голоса и совсем мало шума в звуке), всегда звонкие.
- Б, В, Г, Д, Ж, З – звонкие [б], [в], [г], [д], [ж], [з], [б’], [в’], [г’], [д’], [з’], имеют парные звуки по звонкости/глухости.
- Фраза для запоминания содержит все звонкие согласные: Мы же не забывали друга.
- Глухие
- произносятся без голоса (без колебания голосовых связок) и состоят только из шума:
- П, Ф, К, Т, Ш, С – глухие [п], [ф], [к], [т], [ш], [с], [п’], [ф’], [к’], [т’], [с’] имеют парные звонкие;
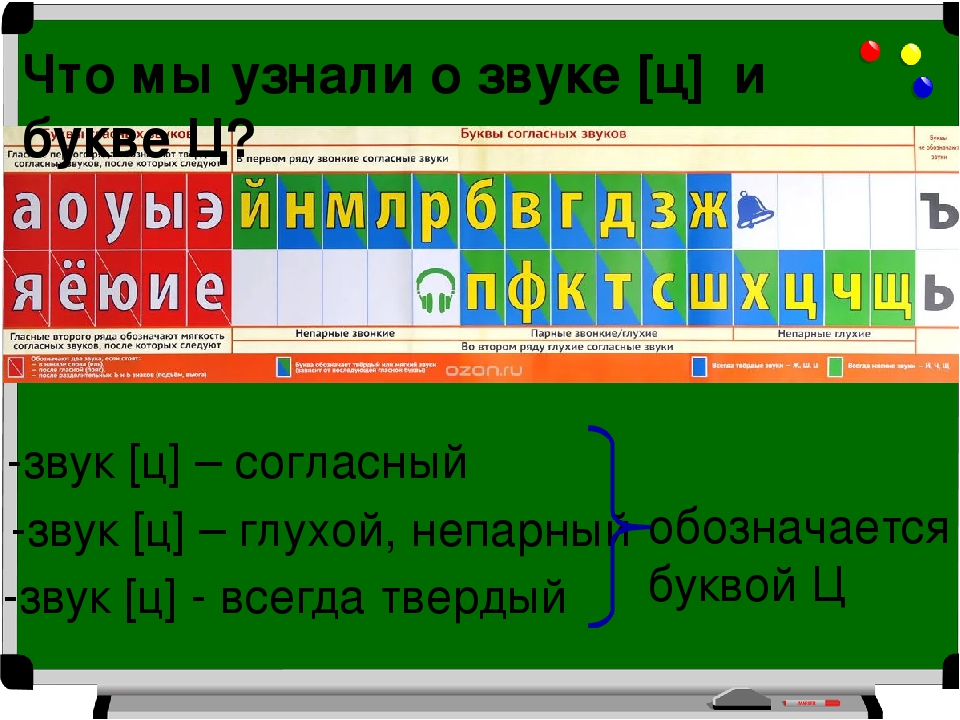
- X, Ц, Ч, Щ – [х], [х’], [ц], [ч’], [щ’] – всегда глухие, не имеют парных по звонкости/глухости .
- Фразы для запоминания, которые содержат все глухие согласные:
- «Степка, хочешь щец?» – «Фи!»
- Фока, хочешь поесть щец?

Для того чтобы определить, звонкий или глухой согласный, ребёнок закрывает уши ладошками и произносит этот звук. Если ребёнок при произнесении слышит голос, то это звонкий согласный. Если слышит не голос, а шум, то этот согласный глухой.
- Твердые: [б], [в], [г], [д], [ж], [з], [к], [л], [м], [н], [п], [р], [с], [т], [ф], [х], [ц], [ш].
- Мягкие: [б’], [в’], [г’], [д’], [з’], [й’], [к’], [л’], [м’], [н’], [п’], [р’], [с’], [т’], [ф’], [х’], [ч’], [щ’]. При фонетическом разборе мягкие звуки обозначаются знаком [‘].
Твердые и мягкие согласные при произношении различаются положением языка. Важно различать для правильного произношения и написания слов: мол [мол] – моль [мол’], угол [угол] – уголь [угол’], нос [нос] – нёс [н’ос].
- Л, М, Н, Р, Й – всегда звонкие.
- Б-П, В-Ф, Г-К, Д-Т, Ж-Ш, З-С – парные согласные по звонкости-глухости.
- X, Ц, Ч, Щ – всегда глухие согласные.
- Ч, Щ, Й – всегда мягкие согласные.
- Ж, Ш, Ц – всегда твердые согласные.
- Ж, Ш,Ч, Щ – шипящие.
ФОНЕТИЧЕСКИЙ (ЗВУКО-БУКВЕННЫЙ) АНАЛИЗ СЛОВА
- Запишите слово.
- Поставьте ударение.
- Разделите слово на слоги. Сосчитайте и запишите их количество.
- Выпишите все буквы этого слова в столбик одну под другой. Сосчитайте и запишите их количество.
- Напишите справа от каждой буквы, в квадратных скобках, звук, который эта буква обозначает.
- Опишите звуки:
- Гласный, ударный или безударный.
- Согласный, глухой или звонкий, парный или непарный; твёрдый или мягкий, парный или непарный.
- Сосчитайте и запишите количество звуков.
- Иногда требуется объяснить особенности правописания (орфографические правила).

Примеры
| ко|леч|ко – 3 слога, 7 б., 7 зв. | ||
|---|---|---|
| К | [к] | согл., глух., тв. |
| О | [а] | глас, безудар. |
| Л | [л’] | согл., звон., мягк. |
| Е | [э] | глас, удар. |
| Ч | [ч’] | согл., глух., мягк. |
| К | [к] | согл., глух., тв. |
| О | [а] | глас, безудар. |
| Ель – 1 слог, 3 б. 3 зв. | ||
| Е | [й’] | согл., звон., мягк. |
| [э] | глас, удар. | |
| Л | [л’] | согл., звон., мягк. |
| Ь | [-] | не обозначает звука, обозначает мягкость предыдущего согласного звука Л |
Обратите внимание !
Для гласных.
- Буквы Я, Ё, Ю, Е – йотированные.
- Если эти буквы стоят после согласных, то они дают один звук:
- Я – [а], Ё – [о], Ю – [у], Е – [э]: Лён – [л’ о н] – 3 буквы, 3 звука.
- Если эти буквы стоят в начале слова, после гласных и разделительных Ъ и Ь знаков, то они дают 2 звука:
- Я – [й’а], Ё – [й’о], Ю – [й’у], Е – [й’э]: Ёлка – [й’ о л к а] – 4 буквы, 5 звуков. Поёт [пай’о т ] – 4 буквы, 5 звуков.
- Если эти буквы стоят после согласных, то они дают один звук:
- Буква И
- после Ь обозначает два звука: чьи [ч’й’и], лисьи [лис’й’и];
- после согласных Ж, Ш, Ц даёт звук [ы]:
- зажим [зажым], шины [ш ы н ы], цирк [цырк] ;
- гласная О под ударением даёт звук [о], а без ударения [а]:
- кОтик – [ кОт ‘ и к], скворцы – [с к в а р ц ы];
- гласная Е под ударением даёт звук [э], а без ударения [и]:
- лес [л’эс], лесА [л’исА] (см. лисА [л’исА]), весна [в’исна];
- лес [л’эс], лесА [л’исА] (см.
- в некоторых иноязычных словах перед гласной Е согласный произносится твёрдо:
- кафе [кафэ], купе [купэ], свитер [свитэр], отель [атэл’];
- гласная Я под ударением даёт звук [а], а без ударения [э], [и]:
- мяч – [м’ач’], рябина – [р’эб’ина], пятно – [п’итно].
- Буквы Я, Ё, Ю, Е – йотированные.

 лисА [л’исА]), весна [в’исна];
лисА [л’исА]), весна [в’исна];Для согласных.
- парные по глухости/звонкости согласные в конце слова, перед глухой согласной произносятся глухо (оглушаются):
- гриб – [гр’ и п], лавка – [л а ф к а];
- Й, Ч, Щ – [й’], [ч’], [щ’] – всегда мягкие;
- Ж, Ш, Ц – [ж], [ш], [ц] – всегда твердые;
- Если в слове рядом стоят несколько согласных, то в некоторых словах звуки [в], [д], [л], [т] не произносятся (непроизносимые согласные), но буквы в,д, л, т пишутся:
- чувство [ч’Уства], солнце [сОнцэ], сердце [с’Эрцэ], радостный [рАдасный’].
- чувство [ч’Уства], солнце [сОнцэ], сердце [с’Эрцэ], радостный [рАдасный’].
- сочетание СТН произносится как [сн], ЗДН – [зн]:
- звёздный – [з в’ о з н ы й’], лестница – [л’ эс ‘н’и ц а].
- иногда на месте буквы Г перед глухой согласной произносятся звуки [к], [х]:
- когти – [к о к т’ и], мягкий – [м’ ах ‘ к ‘ и й’];
- иногда буква С в начале слова перед звонкой согласной озвончается:
- сделал – [з’ д’ э л а л].
- между корнем и суффиксом перед мягкими согласными согласные могут звучать мягко :
- зонтик – [з о н’ т ‘и к];
- иногда буква Н обозначает мягкий согласный звук перед согласными Ч, Щ:
- стаканчик – [с т а к а н’ ч’ и к], сменщик – [см’э н’ щ’ и к];
- Удвоенные согласные располагаются
- после ударного гласного, то дают длинный звук : грУппа [ груп:а], вАнна [ ван:а];
- перед ударным гласным, то образуется обычный согласный звук: миллиОн [м’ил‘иОн], аккОрд [акОрт], аллЕя [ал‘Эй’а] ;
- сочетания ТСЯ, ТЬСЯ (у глаголов) произносятся как длинный [ц]:
- бриться – [бр’ иц:а];
- иногда сочетание ЧН, ЧТ произносится как [ш]:
- конечно – [ кан ‘ эшна ], скучно – [ скушна ], что – [ш т о], чтобы – [штобы];
- буква Щ и сочетания букв СЧ, ЗЧ, ЖЧ обозначают звук [щ’]:
- щавель [щ ‘ав ‘ эл ‘ ], счастливый [ щ ‘асливый ‘ ], извозчик [извощ ‘ик], перебежчик [п ‘ир ‘иб’Эщ ‘ик];
- в окончаниях имён прилагательных ОГО, ЕГО согласный Г произносится как [в]:
- белого – [б’ Э л а в а].
- белого – [б’ Э л а в а].
- парные по глухости/звонкости согласные в конце слова, перед глухой согласной произносятся глухо (оглушаются):


Фонетический разбор / Звуки и буквы / Справочник по русскому языку для начальной школы
- Главная
- Справочники
- Справочник по русскому языку для начальной школы
- Звуки и буквы
- Фонетический разбор
Фонетический разбор — это характеристика каждого звука, из которого состоит слово. Слово, заданное для фонетического разбор, обозначается в тексте цифрой 1, которая ставится после слова для разбора (петь1).
При фонетическом разборе записывается:
! Обрати внимание, что количество букв и звуков в слове могут не совпадать!
Например:
петь [п’эт’] — 4 буквы, но 3 звука (т.к. мягкий знак звука не даёт).
ёж [й’ош] — 2 буквы, но 3 звука (т. к. буква ё в начале слова даёт 2 звука — согласный [й’] и гласный [о]).
к. буква ё в начале слова даёт 2 звука — согласный [й’] и гласный [о]).
Примеры фонетического (звуко-буквенного) разбора:
Багаж1 был сдан в камеру хранения.
Бага́ж [бага́ш] — 2 слога, 5 букв, 5 звуков.
б [б] – звук согласный, звонкий парный, твёрдый парный;
а [а] – звук гласный, безударный;
г [г] – звук согласный, звонкий парный, твёрдый парный;
а [а] – звук гласный, ударный;
ж [ш] – звук согласный, глухой парный, твёрдый непарный.
В полях поспевала золотая рожь1.
Рожь [рош] – 1 слог, 4 буквы, 3 звука.
р [р] – звук согласный, звонкий непарный, твёрдый парный;
о [о] – звук гласный, ударный;
ж [ш] – звук согласный, глухой парный, твёрдый непарный;
ь [-]
По дорожке семенил маленький ёжик1.
Ёжик [й’о́жык] – 1 слог, 4 буквы, 5 звуков.
ё [й’] – звук согласный, звонкий непарный, мягкий непарный;
[о] – звук гласный, ударный;
ж [ж] – звук согласный, звонкий парный, твёрдый непарный;
и [ы] – звук гласный, безударный;
к [к] – звук согласный, глухой парный, твёрдый парный.
Поделись с друзьями в социальных сетях:
Советуем посмотреть:
Алфавит
Гласные звуки и буквы, их обозначающие
Согласные звуки и буквы, их обозначающие
Слог
Ударение
Звуки и буквы
Правило встречается в следующих упражнениях:
1 класс
Упражнение 4, Иванов, Евдокимова, Кузнецова, Учебник
2 класс
Упражнение 46, Канакина, Рабочая тетрадь, часть 2
3 класс
Упражнение 186, Канакина, Горецкий, Учебник, часть 1
Упражнение 263, Канакина, Горецкий, Учебник, часть 1
Упражнение 152, Канакина, Рабочая тетрадь, часть 1
Упражнение 10, Канакина, Горецкий, Учебник, часть 2
Упражнение 42, Канакина, Горецкий, Учебник, часть 2
Упражнение 58, Канакина, Горецкий, Учебник, часть 2
Упражнение 114, Канакина, Горецкий, Учебник, часть 2
Упражнение 171, Канакина, Горецкий, Учебник, часть 2
Упражнение 250, Канакина, Горецкий, Учебник, часть 2
Упражнение 263, Канакина, Горецкий, Учебник, часть 2
4 класс
Упражнение 65, Канакина, Горецкий, Учебник, часть 1
Упражнение 78, Канакина, Горецкий, Учебник, часть 1
Упражнение 245, Канакина, Горецкий, Учебник, часть 1
Упражнение 64, Канакина, Горецкий, Учебник, часть 2
Упражнение 255, Канакина, Горецкий, Учебник, часть 2
Упражнение 29, Климанова, Бабушкина, Учебник, часть 1
Упражнение 2, Бунеев, Бунеева, Пронина, Учебник, часть 1
Упражнение 1, Бунеев, Бунеева, Пронина, Учебник, часть 1
Упражнение 508, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 2
Упражнение 610, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 2
5 класс
Упражнение 311, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Упражнение 340, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Упражнение 32, Разумовская, Львова, Капинос, Учебник
Упражнение 37, Разумовская, Львова, Капинос, Учебник
Упражнение 115, Александрова, Рыбченкова, Глазков, Лисицин, Учебник, часть 1
Упражнение 176, Александрова, Рыбченкова, Глазков, Лисицин, Учебник, часть 1
Упражнение 276, Александрова, Рыбченкова, Глазков, Лисицин, Учебник, часть 2
Упражнение 280, Александрова, Рыбченкова, Глазков, Лисицин, Учебник, часть 2
Упражнение 308, Александрова, Рыбченкова, Глазков, Лисицин, Учебник, часть 2
Упражнение Повторение стр. 81,
Александрова, Рыбченкова, Глазков, Лисицин, Учебник, часть 2
81,
Александрова, Рыбченкова, Глазков, Лисицин, Учебник, часть 2
6 класс
Упражнение 100, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Упражнение 112, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Упражнение 551, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 2
Упражнение 567, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 2
Упражнение 587, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 2
Упражнение 588, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 2
Упражнение 6, Разумовская, Львова, Капинос, Учебник
Упражнение 165, Разумовская, Львова, Капинос, Учебник
Упражнение 721, Разумовская, Львова, Капинос, Учебник
Упражнение 17, Александрова, Рыбченкова, Загоровская, Нарушевич, Учебник, часть 1
7 класс
Упражнение 14, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Александрова, Учебник
Упражнение 338, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Александрова, Учебник
Упражнение 440, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Александрова, Учебник
Упражнение 446, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Александрова, Учебник
Упражнение 452, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Александрова, Учебник
Упражнение 458, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Александрова, Учебник
Упражнение 465, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Александрова, Учебник
Упражнение 505, Разумовская, Львова, Капинос, Учебник
Упражнение 587, Разумовская, Львова, Капинос, Учебник
Упражнение 596, Разумовская, Львова, Капинос, Учебник
8 класс
Упражнение 20, Ладыженская, Тростенцова, Александрова, Дейкина, Учебник
Упражнение 50, Ладыженская, Тростенцова, Александрова, Дейкина, Учебник
Упражнение 172, Ладыженская, Тростенцова, Александрова, Дейкина, Учебник
Упражнение 184, Ладыженская, Тростенцова, Александрова, Дейкина, Учебник
Упражнение 316, Ладыженская, Тростенцова, Александрова, Дейкина, Учебник
Упражнение 370, Ладыженская, Тростенцова, Александрова, Дейкина, Учебник
Упражнение 385, Ладыженская, Тростенцова, Александрова, Дейкина, Учебник
Упражнение 70, Разумовская, Львова, Капинос, Учебник
Упражнение 115, Разумовская, Львова, Капинос, Учебник
Упражнение 258, Разумовская, Львова, Капинос, Учебник
© budu5. com, 2021
com, 2021
Пользовательское соглашение
Copyright
что такое фонетический разбор слова, что значит, как выполнять фонетический разбор, звуко буквенный.
Фонетическим разбором лингвисты называют анализ с позиций слогового состава и качества звуков, из которых состоит слово. Примерно такое определение выдают онлайн-поисковики, и оно вполне соответствует действительности. Фонетический разбор входит в число основных составляющих школьного курса по русскому языку.…
Вконтакте
Google+
Мой мир
Наряду с ним этот курс включает разбор по составу и морфологический разбор. У каждого из этих видов предусмотрены свои основные правила. Полный фонетический разбор слова всем, кто учился в школе, приходилось делать в классе.
Это интересно: спряжения глаголов в русском языке, таблица.

Однако тот, кто покинул учебное заведение давно мог уже забыть, что такое фонетический разбор и каковы его основные правила. Конечно, найти информацию про фонетический разбор слова онлайн при желании не составит труда. Вспомнить об этом задании, которое выпадало на долю каждого начиная с самых младших классов, будет несложно.
Как выполнять фонетический разбор?
Лингвисты рекомендуют, как правило, такую последовательность действий:
- Написать разбираемое слово без ошибок.
- Разделить его по слогам.
- Определить слог под ударением.
- Отразить, как можно его переносить, не разрывая слогов.
- Указать в порядке очерёдности, какие звуки входят в слово.
- Охарактеризовать все звуки по очереди, перечислив их основные характеристики.
- Посчитать и записать, сколько всего букв и звуков.
- Отметить все факты, когда звук и обозначающая его буква не идентичны.
Основная характеристика у гласных одна — расположение под ударением или нет. У согласных их побольше: мягкий или твёрдый, глухой или звонкий, имеет ли пару.
У согласных их побольше: мягкий или твёрдый, глухой или звонкий, имеет ли пару.
Это интересно: односоставные определенно личные предложения, их примеры.
Рекомендации при выполнении фонетического разбора
- Проговаривайте вслух предмет разбора.
- Не забывайте проверить правильность письменной передачи.
- Помните про орфограммы.
- Особое внимание уделяйте сочетаниям звуков одного порядка (гласных или согласных и др.).
Что надо знать, делая фонетический разбор
Для фонетического разбора потребуются некоторые общие сведения об особенностях графической передачи ряда звуков.Поможет сделать фонетический разбор слова таблица соответствия парных звуков. Их немного: б — п, в — ф, г — к, ж — ш, з — с.Ъ (твёрдый знак)и ь (мягкий знак) самостоятельных звуков не отражают, только соответствующим образом иллюстрируют качество согласного перед ними.
Буквы е, ё, ю, я в начальной позиции или после гласного означают два звука — [й] и [э], [о], [у] или [а] соответственно: ящик, плеяда, юла, ёлка, ель .
А вот если они идут после согласного, значит, он мягкий .
Это интересно: примеры и правила написания слова с суффиксом -оньк-.
Исключение составляет е, которая может использоваться в ряде случаев и после твёрдого или передавать звук [э] после гласного (например, проект).
Звуки [о] и [э] не под ударением подвержены явлению , которое в лингвистике называется редукцией: букву о в большинстве случаев читают как [а], а [э] — как [ы].
Вместо звонкого согласного в конце слова или перед глухим звучит парный глухой .
Так, «гриб» произносится [гр’ып].
Звуки [ч’], [ц] и [щ’] не имеют звонких пар , у [л], [м], [н], [р], [й’] нет парных глухих.
Нужно знать! Что такое диалектизм?
Образец фонетического разбора
Приведём несколько примеров.
корабль
ко-рА-бль, три слога, ударный второй
[караб’л’]
К — [к] согласный, твёрдый, глухой, парный
О — [а] гласный, безударный
Р — [р] согласный, твёрдый, звонкий, непарный
А — [а] гласный, ударный
Б — [б’] согласный, мягкий, звонкий, непарный
Л — [л’] согласный, мягкий, звонкий, непарный
Семь букв и шесть звуков.
гриб
грИб, один слог, ударный
[гр’ип]
Г — [г] согласный, твёрдый, звонкий, парный
Р — [р’] согласный, мягкий, звонкий, парный
И — [ы] гласный, ударный
Б — [п] согласный, твёрдый, звонкий, парный
Четыре буквы и четыре звука.
ёж
Ёж, один слог, ударный
[йош]
Ё — [й’] согласный, мягкий, звонкий, непарный
— [о] гласный, ударный
Ж — [ш] согласный, твёрдый, глухой, парный.
Две буквы и три звука.
Что ещё полезно знать?
В зависимости от методики и комплекта учебников, используемых учителями в конкретной школе или классе, формальные требования к фонетическому разбору слова могут слегка варьировать. Однако общие рекомендации в целом едины.В некоторых случаях могут возникать вопросы, как быть с предлогами. Чаще всего на практике их фонетический разбор просто не делается. Хотя на всякий случай будет полезным знать, что обычно предлог как бы примыкает к части речи, которая следует за ним, и при наличии в нём гласных они чаще всего будут безударными.
Например, в сочетании предлога и существительного «по полю» ударным является первый слог в слове «полю», а сама конструкция произносится [папОл’у]. Хотя возможен и вариант [попал’у]. Случаи когда ударение падает на предлог, а не на то, что следует за ним, нечасто, но встречаются. Ярким примером может служить грубо просторечное «по фиг» [пОф’ык].
Такое явление становится возможным, потому что с точки зрения фонетики существительные и предлоги часто воспринимаются не как разные слова, а одно слово и произносятся именно так. В лингвистике это называется фонетическим словом. Впрочем, столь глубокие сведения обычно преподаются уже в курсе фонетики студентам-филологам, а в школе в такие дебри не забираются Ну а каждый, кого заинтересовал этот момент, может найти нужную информацию и примеры онлайн.
В школе ученикам дают задания по фонетическому разбору слов, в первую очередь, для закрепления базовых теоретических познаний, которые они получают от учителя и из книг. В свою очередь, базовые знания фонетики сослужат им хорошую службу в практическом применении языка, то есть правильном его использовании на письме и чтении.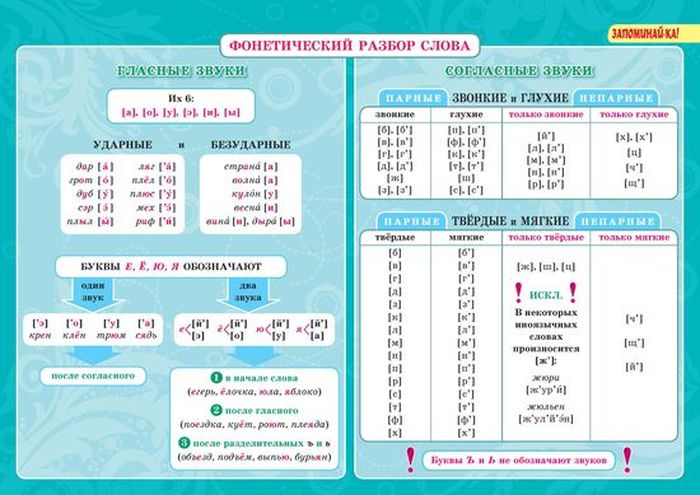 Так, представление о таких языковых явлениях, как особенности произношения звуков в зависимости от позиции, позволяют понять, почему в некоторых случаях надо использовать букву, передающую не тот звук, который слышится.
Так, представление о таких языковых явлениях, как особенности произношения звуков в зависимости от позиции, позволяют понять, почему в некоторых случаях надо использовать букву, передающую не тот звук, который слышится.
Особенную важность фонетика и всё, что с ней связано, приобретает в регионах с ярко выраженными диалектными особенностями. Например, в верхневолжских говорах буква о в безударном положении читается [о], а в южнорусских вследствие особенностей местного произношения звука [г] с придыханием парным ему фактически становится [х]. Однако на уроках русского языка делать фонетический разбор требуется по правилам литературного языка. Это должно помочь ученикам освоить русскую литературную речь. Ведь использование диалекта считается признаком неграмотности.
Как делать фонетический разбор подробно рассказано в видео.
Транскрипция русских слов. Фонетический разбор слова онлайн.
Первый раз здесь?
Посмотрите видео «Как перевести текст в фонетическую транскрипцию и послушать аудиозаписи слов»
Ваш браузер не поддерживает HTML5 видео!
Посмотрите видео «Как создавать списки слов»
Ваш браузер не поддерживает HTML5 видео!
Количество слов в нашем словаре русского произношения
| Тимур | 3 200 слов |
x0. 5 x1 5 x1x0.5 x1 |
|
Оформить подписку
Вы изучаете или преподаете русский?
Мы знаем, что иногда русский язык кажется трудным. Мы не хотим, чтобы вы теряли время.
Ознакомьтесь со всеми нашими инструментами и учите русский быстрее!
Приветствие от создателя сайта Тимура:
Узнайте, как активировать мозг и учиться быстрее (4 мин.)
Ваш браузер не поддерживает HTML5 видео!
Статья Тимура Байтукалова «Учим иностранный язык с нуля. Часть 1. Осваиваем произношение»
Книга Тимура Байтукалова «Быстрое изучение иностранного языка от английского до японского»
Бесплатный вебинар «Фонетическая транскрипция для быстрого изучения иностранных языков» (21 мин.)
Фонетическая транскрипция русских слов
Русское произношение может представлять затруднение даже для людей, для которых русский язык является родным, не говоря уже об иностранцах. Начнем с того, что в словарях фонетическая транскрипция русских слов не указывается. Считается, что правила произношения в русском языке довольно строгие. На самом деле они очень сложные и имеют много исключений.
Начнем с того, что в словарях фонетическая транскрипция русских слов не указывается. Считается, что правила произношения в русском языке довольно строгие. На самом деле они очень сложные и имеют много исключений.
Произношение русских букв меняется в зависимости от того, под ударением находится данная буква или нет (в случае гласных букв), а также от того, какие согласные буквы окружают данную букву. Буква «а», к примеру, может иметь 5 вариантов произношения!
Этот онлайн-переводчик позволяет перевести текст на русском языке в фонетическую транскрипцию, записанную либо буквами кириллицы, либо символами международного фонетического алфавита (МФА).
Фонетический разбор слова онлайн
Переводчик может быть использован для фонетического разбора слова онлайн. Чтобы произвести фонетический разбор слова, вам нужно:
- записать слово.
- поставить ударение в слове (переводчик умеет это делать).
- разделить слово на слоги.
- записать фонетическую транскрипцию слова (здесь вам также пригодится переводчик).
- записать все буквы слова в столбик.
- записать справа от каждой буквы звук, который данная буква обозначает.
- описать звук: для гласных – ударный или безударный, для согласных – твердый или мягкий (парный/непарный), глухой или звонкий (парный/непарный).
- посчитать буквы и звуки в слове.

Произведем, к примеру, фонетический разбор слова «солнце»:
со́-лнце [со́нцыэ]
| с | с | согласный, твердый парный, глухой парный |
| о | о | гласный, ударный |
| л | не читается | |
| н | н | согласный, твердый парный, звонкий непарный |
| ц | ц | согласный, твердый непарный, глухой непарный |
| е | ыэ | гласный, безударный |
6 букв, 5 звуков.
Обратите внимание на последний звук слова – в школьной практике его записали бы как «э». Профессиональные лингвисты обозначают его как «ыэ«, т.к. этот безударный гласный произносится как нечто среднее между звуками «ы» и «э».
Фонетическая транскрипция поможет иностранцам улучшить произношение русских слов
Если вы учите русский язык, этот инструмент послужит вам руководством по произношению русского языка, и поможет вам сэкономить время на первых порах освоения русского, пока вы еще не освоили правила произношения.
Если вы регулярно пользуетесь фонетической транскрипцией в сочетании с аудио- и видеоматериалами на русском языке, вы быстро сможете улучшить свое русское произношение и навыки аудирования.
Чтобы помочь вам, мы создали раздел видео-тренажер русского произношения. Он позволяет тренировать произношение наиболее часто встречающихся русских слов, задавать скорость воспроизведения и количество повторений каждого слова.
Еще один отличный способ улучшить русское произношение — воспользоваться разделом сайта «Учим русские слова по видео». Он предназначен для начинающих и имеет русские субтитры для всех уроков.
Дополнительная информация о переводчике
Некоторые русские слова с одинаковым написанием могут иметь разное значение в зависимости от ударения. Cравните: замо́к – за́мок. Эти слова называются «омографы». Наш переводчик выделит транскрипцию таких слов зеленым цветом. Например:
Если вы наведете мышкой на такое слово или коснетесь его на вашем мобильном устройстве, вы увидите все возможные произношения.
Переводчик работает на основе словаря, содержащего информацию об ударениях в русских словах. Если положение ударения для данного слова не было найдено в словаре, то вместо транскрипции будет показано само слово, окруженное косыми чертами: /экстравагантный/. Вы можете улучшить переводчик, указав положения ударения в подобных словах. Для этого перейдите в режим исправления ошибок.
Для этого перейдите в режим исправления ошибок.
При создании переводчика мы использовали онлайн-ресурсы из списка ниже, а также книгу Буланина «Фонетика современного русского языка».
Кириллическая транскрипция
Кириллическая транскрипция — не самый точный способ передачи того, как произносятся русские слова. Тем не менее, ее часто изучают в ВУЗах. В таблице ниже вы найдете соответствия кириллической транскрипции некоторым символам международного фонетического алфавита:
| Символ международного фонетического алфавита | Кириллическая транскрипция |
|---|---|
| ударный гласный [ˈe] | [э́] |
| ударный гласный [ˈʉ] | [у́] |
| безударный гласный [ʉ] | [у] |
| заударный гласный [ə] после твердых согласных в абсолютном конце | [ʌ] |
| безударный гласный [ɪ] | [ие] в первом предударном слоге и в абсолютном начале слова, [ь] в остальных безударных слогах |
Выделение цветом часто встречающихся русских слов
Специальная опция позволяет вам выделять различными цветами наиболее часто встречающиеся русские слова. В зависимости от рейтинга частотности слова будут выделены следующими цветами:
В зависимости от рейтинга частотности слова будут выделены следующими цветами:
| 1-1000 | 1001-2000 | 2001-3000 | 3001-4000 | 4001-5000 |
Если вы хотите осуществить детальный анализ вашего текста и увидеть подробную статистику, вы можете воспользоваться онлайн-инструментом для частотного анализа текста на русском языке.
Возможно, вас заинтересует фонетический конвертер русских субтитров. С его помощью вы можете получить следующий результат:
Транскрипция русских слов – онлайн-ресурсы
Обновления этого переводчика слов в транскрипцию
Поиск в блоге
Ясень — фонетический (звуко-буквенный) разбор слова
Делая фонетический разбор, ребенок учится различать графический облик слова и его звучание. Опираясь на знание фонетики, он может объяснить, почему слово пишется и звучит по-разному. Таким образом, звуко-буквенный разбор формирует способность анализировать, повышает общую орфографическую грамотность.
При разборе слов с буквами «я», «е» обязательно вспомните, что у них несколько задач. Эти буквы обозначают:
- Один гласный, когда стоят после согласных
- Два звука: [й’] и гласный, в позиции абсолютного начала слова, после гласных или после Ь и Ъ
- Мягкость предыдущего согласного
Слово «ясень» начинается с буквы «я», значит, первый звук — [й’], а «е» стоит после согласного, значит надо обратить внимание на его мягкость.
Фонетическая транскрипция
В этом слове два слога: я’-сень; ударный — первый.
[й’а́с’и н’]
Характеристика звуков
я -[й’] – согласн., звонкий, мягк.;
[а́] – гласн., ударный;
с — [с’] – согласн., глухой, мягк.;
е — [и] – гласн., безударный;
н — [н’] – согласн., звонкий, мягк.;
ь — не имеет звука.
Гласные
Буква «я» стоит в сильной позиции: в начале слова и под ударением. Поэтому услышать гласный звук, который она обозначает, не составит труда. Это ударный [а́].
Это ударный [а́].
А вот «е» стоит в слабой позиции, потому что находится после ударного слога. Поэтому надо либо вслушаться, чтобы определить звук правильно, либо помнить, что в слабой позиции она может обозначать только [и]. Если на уроках используется термин «редуцированный звук», то речь именно об этом.
Итак, в слове два гласных:
- [а́] – ударный
- [и] – безударный
Согласные
«Я» стоит в абсолютном начале, поэтому первый звук, который мы произносим, [й’]. Две согласных, «с» и «н», являются мягкими. В первом случае мягкость обозначается буквой «е», во втором – «ь».
[й’] – звонкий, мягк.
[с’] – глухой, мягк.
[н’] — звонкий, мягк.
Примеры разбора
Ученик должен уметь оформить работу письменно или дать устный ответ.
Устный разбор слова
Слово «ясень» состоит из двух слогов: я’-сень. Первый слог — ударный
В слове два гласных звука:
- [а́] — ударный. Обозначается на письме буквой «я»
- [и] – безударный. Обозначается на письме буквой «е»
 Обозначается на письме буквой «е»
Обозначается на письме буквой «е»И три согласных звука:
- [й’] – звонкий, мягкий, обозначается буквой «я»
- [с’] – глухой, мягкий, обозначается «с»
- [н’] — звонкий, мягкий, обозначается «н»
В разбираемом слове количество букв и звуков совпадает, потому что «я» обозначает два звука, а «ь» — ни одного.
Письменный разбор
Ясень – я’-сень, 2 слога
я – [й’] – согласный, звонкий, мягкий;
[а́] – гласный, ударный;
с — [с’] – согласный, глухой, мягкий;
е — [и] – гласный, безударный;
н — [н’] — согласный, звонкий, мягкий;
ь — не имеет звука.
5 б., 5 зв.
% PDF-1.3 % 1 0 obj > / Метаданные 2 0 R / Контуры 3 0 R / PageLayout / OneColumn / Страницы 4 0 R / StructTreeRoot 5 0 R / Тип / Каталог >> эндобдж 6 0 obj /Комментарии () /Компания () / CreationDate (D: 201
163752 + 03’00 ‘) / Creator (Acrobat PDFMaker 15 для Word) / Ключевые слова () / Mendeley # 20Citation # 20Style_1 (http://www. zotero.org/styles/association-for-computational-linguistics)
/ Mendeley # 20Document_1 (Верно)
/ Mendeley # 20Recent # 20Style # 20Id # 200_1 (http://www.zotero.org/styles/apa)
/ Mendeley # 20Recent # 20Style # 20Id # 201_1 (http: // www.zotero.org/styles/american-sociological-association)
/ Mendeley # 20Recent # 20Style # 20Id # 202_1 (http://www.zotero.org/styles/association-for-computational-linguistics)
/ Mendeley # 20Recent # 20Style # 20Id # 203_1 (http://www.zotero.org/styles/chicago-author-date)
/ Mendeley # 20Recent # 20Style # 20Id # 204_1 (http://www.zotero.org/styles/chicago-fullnote-bibliography)
/ Mendeley # 20Recent # 20Style # 20Id # 205_1 (http://www.zotero.org/styles/harvard1)
/ Mendeley # 20Recent # 20Style # 20Id # 206_1 (http://www.zotero.org/styles/modern-humanities-research-association)
/ Mendeley # 20Recent # 20Style # 20Id # 207_1 (http: // www.zotero.org/styles/modern-language-association)
/ Mendeley # 20Recent # 20Style # 20Id # 208_1 (http://www.zotero.org/styles/modern-language-association-8th-edition)
/ Mendeley # 20Recent # 20Style # 20Id # 209_1 (http://www.
zotero.org/styles/association-for-computational-linguistics)
/ Mendeley # 20Document_1 (Верно)
/ Mendeley # 20Recent # 20Style # 20Id # 200_1 (http://www.zotero.org/styles/apa)
/ Mendeley # 20Recent # 20Style # 20Id # 201_1 (http: // www.zotero.org/styles/american-sociological-association)
/ Mendeley # 20Recent # 20Style # 20Id # 202_1 (http://www.zotero.org/styles/association-for-computational-linguistics)
/ Mendeley # 20Recent # 20Style # 20Id # 203_1 (http://www.zotero.org/styles/chicago-author-date)
/ Mendeley # 20Recent # 20Style # 20Id # 204_1 (http://www.zotero.org/styles/chicago-fullnote-bibliography)
/ Mendeley # 20Recent # 20Style # 20Id # 205_1 (http://www.zotero.org/styles/harvard1)
/ Mendeley # 20Recent # 20Style # 20Id # 206_1 (http://www.zotero.org/styles/modern-humanities-research-association)
/ Mendeley # 20Recent # 20Style # 20Id # 207_1 (http: // www.zotero.org/styles/modern-language-association)
/ Mendeley # 20Recent # 20Style # 20Id # 208_1 (http://www.zotero.org/styles/modern-language-association-8th-edition)
/ Mendeley # 20Recent # 20Style # 20Id # 209_1 (http://www.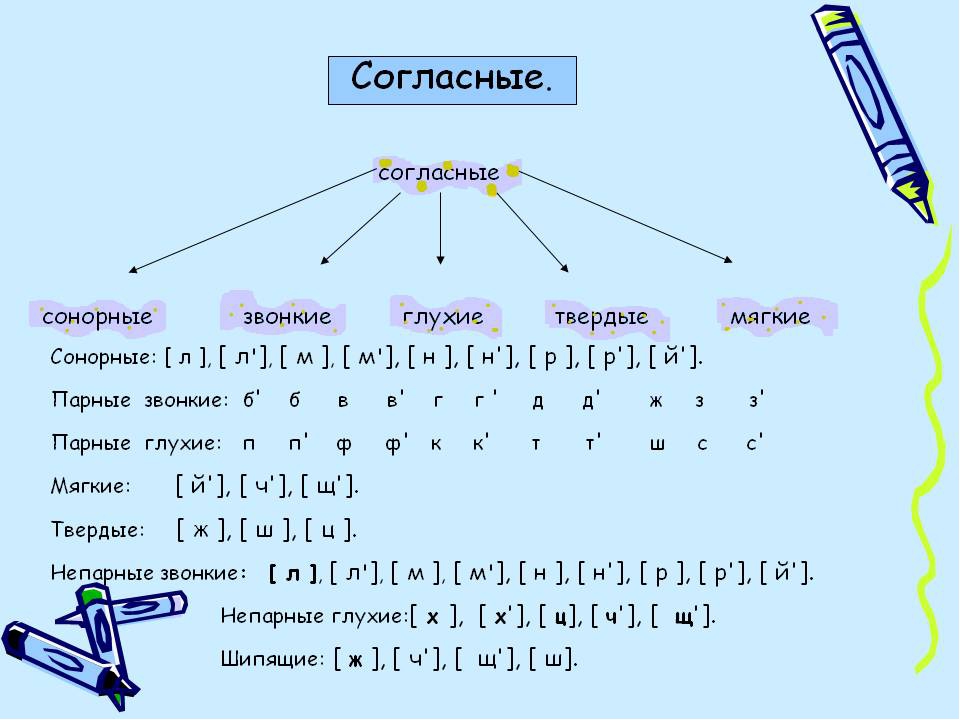 zotero.org/styles/national-library-of-medicine)
/ Mendeley # 20Recent # 20Style # 20Name # 200_1 (6-е издание Американской психологической ассоциации)
/ Mendeley # 20Recent # 20Style # 20Name # 201_1 (Американская социологическая ассоциация)
/ Mendeley # 20Recent # 20Style # 20Name # 202_1 (Ассоциация компьютерной лингвистики — Материалы конференции)
/ Mendeley # 20Recent # 20Style # 20Name # 203_1 (Чикагское руководство по стилю, 16-е издание \ (автор-дата \))
/ Mendeley # 20Recent # 20Style # 20Name # 204_1 (Чикагское руководство по стилю, 16-е издание \ (полное примечание \))
/ Mendeley # 20Recent # 20Style # 20Name # 205_1 (Гарвардский справочный формат 1 \ (автор-дата \))
/ Mendeley # 20Recent # 20Style # 20Name # 206_1 (3-е издание Ассоциации современных гуманитарных исследований \ (примечание с библиографией \))
/ Mendeley # 20Recent # 20Style # 20Name # 207_1 (7-е издание Ассоциации современного языка)
/ Mendeley # 20Recent # 20Style # 20Name # 208_1 (Ассоциация современного языка, 8-е издание)
/ Mendeley # 20Recent # 20Style # 20Name # 209_1 (Национальная медицинская библиотека)
/ Mendeley # 20Unique # 20User # 20Id_1 (810f99f5-889b-3038-b853-920f1c2e3f8a)
/ ModDate (D: 201163758 + 03’00 ‘)
/ Производитель (Adobe PDF Library 15.
zotero.org/styles/national-library-of-medicine)
/ Mendeley # 20Recent # 20Style # 20Name # 200_1 (6-е издание Американской психологической ассоциации)
/ Mendeley # 20Recent # 20Style # 20Name # 201_1 (Американская социологическая ассоциация)
/ Mendeley # 20Recent # 20Style # 20Name # 202_1 (Ассоциация компьютерной лингвистики — Материалы конференции)
/ Mendeley # 20Recent # 20Style # 20Name # 203_1 (Чикагское руководство по стилю, 16-е издание \ (автор-дата \))
/ Mendeley # 20Recent # 20Style # 20Name # 204_1 (Чикагское руководство по стилю, 16-е издание \ (полное примечание \))
/ Mendeley # 20Recent # 20Style # 20Name # 205_1 (Гарвардский справочный формат 1 \ (автор-дата \))
/ Mendeley # 20Recent # 20Style # 20Name # 206_1 (3-е издание Ассоциации современных гуманитарных исследований \ (примечание с библиографией \))
/ Mendeley # 20Recent # 20Style # 20Name # 207_1 (7-е издание Ассоциации современного языка)
/ Mendeley # 20Recent # 20Style # 20Name # 208_1 (Ассоциация современного языка, 8-е издание)
/ Mendeley # 20Recent # 20Style # 20Name # 209_1 (Национальная медицинская библиотека)
/ Mendeley # 20Unique # 20User # 20Id_1 (810f99f5-889b-3038-b853-920f1c2e3f8a)
/ ModDate (D: 201163758 + 03’00 ‘)
/ Производитель (Adobe PDF Library 15. 0)
/ SourceModified (D: 201133745)
/Предмет
/Заголовок
/ rgid (PB: 337293681_AS: 8258009
0)
/ SourceModified (D: 201133745)
/Предмет
/Заголовок
/ rgid (PB: 337293681_AS: 8258009378 @ 1573897707559) >> эндобдж 2 0 obj > поток 2019-08-16T16: 37: 58 + 03: 002019-08-16T16: 37: 52 + 03: 002019-08-16T16: 37: 58 + 03: 00Acrobat PDFMaker 15 для Worduuid: 4fbdbd3c-7823-4cf4-b7ce- d8e641d3bb84uuid: 83770ee4-2014-4be5-96f7-059c02b6c3ed
 zotero.org/styles/association-for-computational-linguisticsↂ0020Recentↂ0020Styleↂ0020Idↂ00202_1>
Association for Computational Linguistics — Conference Proceedingsↂ0020Recentↂ0020Styleↂ0020Nameↂ00202_1>
http: // www.zotero.org/styles/chicago-author-dateↂ0020Recentↂ0020Styleↂ0020Idↂ00203_1>
Чикагское руководство по стилю, 16-е издание (дата автора) ↂ0020Recentↂ0020Styleↂ0020Nameↂ00203_1>
http://www.zotero.org/styles/chicago-fullnote-bibliographyↂ0020Recentↂ0020Styleↂ0020Idↂ00204_1>
Чикагское руководство по стилю, 16-е издание (полное примечание) ↂ0020Recentↂ0020Styleↂ0020Nameↂ00204_1>
http://www.zotero.org/styles/harvard1ↂ0020Recentↂ0020Styleↂ0020Idↂ00205_1>
Гарвардский справочный формат 1 (автор-дата) ↂ0020Recentↂ0020Styleↂ0020Nameↂ00205_1>
http: // www.zotero.org/styles/modern-humanities-research-associationↂ0020Recentↂ0020Styleↂ0020Idↂ00206_1>
3-е издание Ассоциации современных гуманитарных исследований (примечание с библиографией) ↂ0020Recentↂ0020Styleↂ0020Nameↂ00206_1>
http://www.
zotero.org/styles/association-for-computational-linguisticsↂ0020Recentↂ0020Styleↂ0020Idↂ00202_1>
Association for Computational Linguistics — Conference Proceedingsↂ0020Recentↂ0020Styleↂ0020Nameↂ00202_1>
http: // www.zotero.org/styles/chicago-author-dateↂ0020Recentↂ0020Styleↂ0020Idↂ00203_1>
Чикагское руководство по стилю, 16-е издание (дата автора) ↂ0020Recentↂ0020Styleↂ0020Nameↂ00203_1>
http://www.zotero.org/styles/chicago-fullnote-bibliographyↂ0020Recentↂ0020Styleↂ0020Idↂ00204_1>
Чикагское руководство по стилю, 16-е издание (полное примечание) ↂ0020Recentↂ0020Styleↂ0020Nameↂ00204_1>
http://www.zotero.org/styles/harvard1ↂ0020Recentↂ0020Styleↂ0020Idↂ00205_1>
Гарвардский справочный формат 1 (автор-дата) ↂ0020Recentↂ0020Styleↂ0020Nameↂ00205_1>
http: // www.zotero.org/styles/modern-humanities-research-associationↂ0020Recentↂ0020Styleↂ0020Idↂ00206_1>
3-е издание Ассоциации современных гуманитарных исследований (примечание с библиографией) ↂ0020Recentↂ0020Styleↂ0020Nameↂ00206_1>
http://www. zotero.org/styles/modern-language-associationↂ0020Recentↂ0020Styleↂ0020Idↂ00207_1>
Ассоциация современного языка, 7-е изданиеↂ0020Недавнееↂ0020Стильↂ0020Названиеↂ00207_1>
http://www.zotero.org/styles/modern-language-association-8th-editionↂ0020Recentↂ0020Styleↂ0020Idↂ00208_1>
Ассоциация современного языка, 8-е изданиеↂ0020Недавнееↂ0020Стильↂ0020Названиеↂ00208_1>
http: // www.zotero.org/styles/national-library-of-medicineↂ0020Recentↂ0020Styleↂ0020Idↂ00209_1>
Национальная медицинская библиотекаↂ0020Recentↂ0020Styleↂ0020Nameↂ00209_1> конечный поток
эндобдж
3 0 obj
>
эндобдж
4 0 obj
>
эндобдж
5 0 obj
>
эндобдж
7 0 объект
>
эндобдж
8 0 объект
>
эндобдж
9 0 объект
>
/ XObject>
/ Шрифт>
>>
/ MediaBox [0 0 594.
zotero.org/styles/modern-language-associationↂ0020Recentↂ0020Styleↂ0020Idↂ00207_1>
Ассоциация современного языка, 7-е изданиеↂ0020Недавнееↂ0020Стильↂ0020Названиеↂ00207_1>
http://www.zotero.org/styles/modern-language-association-8th-editionↂ0020Recentↂ0020Styleↂ0020Idↂ00208_1>
Ассоциация современного языка, 8-е изданиеↂ0020Недавнееↂ0020Стильↂ0020Названиеↂ00208_1>
http: // www.zotero.org/styles/national-library-of-medicineↂ0020Recentↂ0020Styleↂ0020Idↂ00209_1>
Национальная медицинская библиотекаↂ0020Recentↂ0020Styleↂ0020Nameↂ00209_1> конечный поток
эндобдж
3 0 obj
>
эндобдж
4 0 obj
>
эндобдж
5 0 obj
>
эндобдж
7 0 объект
>
эндобдж
8 0 объект
>
эндобдж
9 0 объект
>
/ XObject>
/ Шрифт>
>>
/ MediaBox [0 0 594. 95996 840.95996]
/ Аннотации [32 0 R 33 0 R 34 0 R 35 0 R 36 0 R 37 0 R 38 0 R 39 0 R 40 0 R 41 0 R]
/ Содержание 42 0 руб.
/ StructParents 0
/ Родитель 4 0 R
>>
эндобдж
10 0 obj
>
/ Шрифт>
/ XObject>
>>
/ Повернуть 0
/ StructParents 0
/ Вкладки / S
/ Тип / Страница
>>
эндобдж
11 0 объект
>
/ ExtGState>
/ Шрифт>
/ XObject>
>>
/ Повернуть 0
/ StructParents 6
/ Вкладки / S
/ Тип / Страница
>>
эндобдж
12 0 объект
>
/ Шрифт>
/ XObject>
>>
/ Повернуть 0
/ StructParents 12
/ Вкладки / S
/ Тип / Страница
>>
эндобдж
13 0 объект
>
/ ExtGState>
/ Шрифт>
/ XObject>
>>
/ Повернуть 0
/ StructParents 22
/ Вкладки / S
/ Тип / Страница
>>
эндобдж
14 0 объект
>
/ ExtGState>
/ Шрифт>
/ XObject>
>>
/ Повернуть 0
/ StructParents 29
/ Вкладки / S
/ Тип / Страница
>>
эндобдж
15 0 объект
>
/ Шрифт>
/ XObject>
>>
/ Повернуть 0
/ StructParents 36
/ Вкладки / S
/ Тип / Страница
>>
эндобдж
16 0 объект
>
/ Шрифт>
/ XObject>
>>
/ Повернуть 0
/ StructParents 44
/ Вкладки / S
/ Тип / Страница
/ Аннотации [138 0 R]
>>
эндобдж
17 0 объект
>
эндобдж
18 0 объект
>
эндобдж
19 0 объект
>
эндобдж
20 0 объект
>
эндобдж
21 0 объект
>
эндобдж
22 0 объект
>
эндобдж
23 0 объект
>
эндобдж
24 0 объект
>
эндобдж
25 0 объект
>
эндобдж
26 0 объект
>
эндобдж
27 0 объект
>
поток
xyp} h if & i22S4dIҤMIv1M6N2iCMdhJƷ | `cc | bԧ $> uCƦHZmp: ˫ Z ~ Ϯ} ww? ~ _R
95996 840.95996]
/ Аннотации [32 0 R 33 0 R 34 0 R 35 0 R 36 0 R 37 0 R 38 0 R 39 0 R 40 0 R 41 0 R]
/ Содержание 42 0 руб.
/ StructParents 0
/ Родитель 4 0 R
>>
эндобдж
10 0 obj
>
/ Шрифт>
/ XObject>
>>
/ Повернуть 0
/ StructParents 0
/ Вкладки / S
/ Тип / Страница
>>
эндобдж
11 0 объект
>
/ ExtGState>
/ Шрифт>
/ XObject>
>>
/ Повернуть 0
/ StructParents 6
/ Вкладки / S
/ Тип / Страница
>>
эндобдж
12 0 объект
>
/ Шрифт>
/ XObject>
>>
/ Повернуть 0
/ StructParents 12
/ Вкладки / S
/ Тип / Страница
>>
эндобдж
13 0 объект
>
/ ExtGState>
/ Шрифт>
/ XObject>
>>
/ Повернуть 0
/ StructParents 22
/ Вкладки / S
/ Тип / Страница
>>
эндобдж
14 0 объект
>
/ ExtGState>
/ Шрифт>
/ XObject>
>>
/ Повернуть 0
/ StructParents 29
/ Вкладки / S
/ Тип / Страница
>>
эндобдж
15 0 объект
>
/ Шрифт>
/ XObject>
>>
/ Повернуть 0
/ StructParents 36
/ Вкладки / S
/ Тип / Страница
>>
эндобдж
16 0 объект
>
/ Шрифт>
/ XObject>
>>
/ Повернуть 0
/ StructParents 44
/ Вкладки / S
/ Тип / Страница
/ Аннотации [138 0 R]
>>
эндобдж
17 0 объект
>
эндобдж
18 0 объект
>
эндобдж
19 0 объект
>
эндобдж
20 0 объект
>
эндобдж
21 0 объект
>
эндобдж
22 0 объект
>
эндобдж
23 0 объект
>
эндобдж
24 0 объект
>
эндобдж
25 0 объект
>
эндобдж
26 0 объект
>
эндобдж
27 0 объект
>
поток
xyp} h if & i22S4dIҤMIv1M6N2iCMdhJƷ | `cc | bԧ $> uCƦHZmp: ˫ Z ~ Ϯ} ww? ~ _R Таблица для сопоставления фонетического английского языка с бенгальским
Контекст 1
. .. Предлагаемый текстовый процессор на бенгальском языке помогает пользователю составить слово, используя нормальное произношение или, лучше сказать, сопоставление бенгальских слов с нормальным английским вводом в соответствии с произношением. Система состоит из трех частей: части графического интерфейса, парсера и базы данных. В этой предлагаемой системе, когда пользователь вводит ввод, данное текущее слово ввода передается синтаксическому анализатору. Затем синтаксический анализатор анализирует это входное слово на его эквивалентное слово на бенгальском языке или часть слова соответственно. Это проанализированное слово или часть слова передается в модуль базы данных, и этот модуль будет искать бенгальские слова, очень похожие на проанализированное слово из доступной базы данных, и предоставит пользователю список возможных слов.Из этого списка пользователь может выбрать желаемое слово и вставить его в текущую позицию или заменить слово, редактируемое в данный момент, двойным щелчком по слову, показанному в списке.
.. Предлагаемый текстовый процессор на бенгальском языке помогает пользователю составить слово, используя нормальное произношение или, лучше сказать, сопоставление бенгальских слов с нормальным английским вводом в соответствии с произношением. Система состоит из трех частей: части графического интерфейса, парсера и базы данных. В этой предлагаемой системе, когда пользователь вводит ввод, данное текущее слово ввода передается синтаксическому анализатору. Затем синтаксический анализатор анализирует это входное слово на его эквивалентное слово на бенгальском языке или часть слова соответственно. Это проанализированное слово или часть слова передается в модуль базы данных, и этот модуль будет искать бенгальские слова, очень похожие на проанализированное слово из доступной базы данных, и предоставит пользователю список возможных слов.Из этого списка пользователь может выбрать желаемое слово и вставить его в текущую позицию или заменить слово, редактируемое в данный момент, двойным щелчком по слову, показанному в списке. Этот процесс будет продолжаться всякий раз, когда пользователь нажимает клавишу для редактирования слова. На рисунках 3 и 4 показаны системные рамки и графический интерфейс предлагаемого текстового процессора на бенгальском языке. Система интерфейса содержит текстовое поле, которое будет принимать ввод от пользователя, а для редактирования система предоставит окно списка, содержащее предсказанные слова, и сетку данных, содержащую доступные слова из базы данных.Чтобы преобразовать слово из фонетического английского языка в бенгальский, в предлагаемой системе используется концепция обработки естественного языка для формирования синтаксического анализатора. Парсер — это программа, которая разделяет код на функциональные компоненты. Ввод в этот синтаксический анализатор осуществляется через клавиатуру в виде фонетического английского языка. Фонетическое письмо — это система, в которой используется уникальный символ для обозначения каждого телефона (звука) языка или диалекта. В случае фонетического бенгальского бенгальские слова разбиваются на слоги (униграммы, биграммы и т.
Этот процесс будет продолжаться всякий раз, когда пользователь нажимает клавишу для редактирования слова. На рисунках 3 и 4 показаны системные рамки и графический интерфейс предлагаемого текстового процессора на бенгальском языке. Система интерфейса содержит текстовое поле, которое будет принимать ввод от пользователя, а для редактирования система предоставит окно списка, содержащее предсказанные слова, и сетку данных, содержащую доступные слова из базы данных.Чтобы преобразовать слово из фонетического английского языка в бенгальский, в предлагаемой системе используется концепция обработки естественного языка для формирования синтаксического анализатора. Парсер — это программа, которая разделяет код на функциональные компоненты. Ввод в этот синтаксический анализатор осуществляется через клавиатуру в виде фонетического английского языка. Фонетическое письмо — это система, в которой используется уникальный символ для обозначения каждого телефона (звука) языка или диалекта. В случае фонетического бенгальского бенгальские слова разбиваются на слоги (униграммы, биграммы и т. Д.) В соответствии с их произношением.В этом текстовом процессоре синтаксический анализатор работает как основная часть приложения, потому что это часть, которая генерирует комбинации символов ASCII, соответствующие бенгальскому слову, которое пользователи хотели написать на самом деле. Когда пользователь вставляет слово фонетически, синтаксический анализатор разбивает слово на фонемы и заменяет фонемы желаемыми комбинациями символов ASCII, используя некоторые сопоставления, указанные в синтаксическом анализаторе. Пример используемых здесь сопоставлений ASCII показан на рисунке 5 ниже: синтаксический анализатор принимает слово или часть слова в качестве входных данных от пользователя, анализирует их слева направо и ищет слоги в слове в такая же мода.Он ищет слоги от большого к маленькому, что означает, что он сначала будет искать специальную последовательность символов, затем биграммы и, наконец, униграммы. Эта политика применяется для того, чтобы найти лучшее совпадение для более точного образования слогов из слова.
Д.) В соответствии с их произношением.В этом текстовом процессоре синтаксический анализатор работает как основная часть приложения, потому что это часть, которая генерирует комбинации символов ASCII, соответствующие бенгальскому слову, которое пользователи хотели написать на самом деле. Когда пользователь вставляет слово фонетически, синтаксический анализатор разбивает слово на фонемы и заменяет фонемы желаемыми комбинациями символов ASCII, используя некоторые сопоставления, указанные в синтаксическом анализаторе. Пример используемых здесь сопоставлений ASCII показан на рисунке 5 ниже: синтаксический анализатор принимает слово или часть слова в качестве входных данных от пользователя, анализирует их слева направо и ищет слоги в слове в такая же мода.Он ищет слоги от большого к маленькому, что означает, что он сначала будет искать специальную последовательность символов, затем биграммы и, наконец, униграммы. Эта политика применяется для того, чтобы найти лучшее совпадение для более точного образования слогов из слова. Когда будет найдено наилучшее совпадение, слог будет заменен соответствующими ему комбинациями символов бенгальского ASCII. Этот процесс повторяется до тех пор, пока не будет достигнут конец слова. Пример разбиения по словам показан на рисунке 6.После каждого завершения синтаксического анализа проанализированное бенгальское слово или последовательность символов ASCII передаются в модуль извлечения данных. База данных бенгальских слов содержит таблицу данных, которая содержит два столбца: одно именованное слово, содержащее бенгальские слова, и еще один столбец с именем типа, оставленный для будущего использования, который будет отображать тип слов. База данных хранит фактические бенгальские слова в базе данных в их эквиваленте ASCII. Чтобы ввести слово в базу данных, мы сначала должны знать точные значения ASCII, сопоставленные с каждым из бенгальских глифов, которые будут здесь использоваться.Структура модуля базы данных показана на рисунке 7. Используя эти определенные знания, бенгальские слова преобразуются в последовательность символов ASCII, а затем эта последовательность вставляется в базу данных.
Когда будет найдено наилучшее совпадение, слог будет заменен соответствующими ему комбинациями символов бенгальского ASCII. Этот процесс повторяется до тех пор, пока не будет достигнут конец слова. Пример разбиения по словам показан на рисунке 6.После каждого завершения синтаксического анализа проанализированное бенгальское слово или последовательность символов ASCII передаются в модуль извлечения данных. База данных бенгальских слов содержит таблицу данных, которая содержит два столбца: одно именованное слово, содержащее бенгальские слова, и еще один столбец с именем типа, оставленный для будущего использования, который будет отображать тип слов. База данных хранит фактические бенгальские слова в базе данных в их эквиваленте ASCII. Чтобы ввести слово в базу данных, мы сначала должны знать точные значения ASCII, сопоставленные с каждым из бенгальских глифов, которые будут здесь использоваться.Структура модуля базы данных показана на рисунке 7. Используя эти определенные знания, бенгальские слова преобразуются в последовательность символов ASCII, а затем эта последовательность вставляется в базу данных. При выполнении противоположной работы, то есть при извлечении символов из базы данных. , проанализированное слово проверяется на наличие этих специальных символов, и при обнаружении они соответственно заменяются. После завершения процесса извлечения эти данные будут скопированы в Data-Grid. Сетка данных используется здесь для облегчения доступа к данным.Наконец, извлеченные данные по одной вставляются в список для доступа пользователя. В окне списка слова отображаются на бенгальском языке, что позволяет пользователю выбрать желаемое слово и вставить его в текущую позицию, дважды щелкнув по нему. Выбранное слово заменит редактируемое слово. В этом подходе предлагается новый метод стеганографии текста для английского языка [31, 32]. В этом методе текст обложки и секретное сообщение генерируются пользователем. Текст Stego формируется путем сопоставления двоичной последовательности секретного сообщения посредством изменения текстуры / рисунка некоторых алфавитов текста обложки.На рисунках 8 и 9 ниже, соответственно, показана последовательность отображения для встраивания 0 и 1 посредством следующих изменений шаблона следующих алфавитов текста обложки.
При выполнении противоположной работы, то есть при извлечении символов из базы данных. , проанализированное слово проверяется на наличие этих специальных символов, и при обнаружении они соответственно заменяются. После завершения процесса извлечения эти данные будут скопированы в Data-Grid. Сетка данных используется здесь для облегчения доступа к данным.Наконец, извлеченные данные по одной вставляются в список для доступа пользователя. В окне списка слова отображаются на бенгальском языке, что позволяет пользователю выбрать желаемое слово и вставить его в текущую позицию, дважды щелкнув по нему. Выбранное слово заменит редактируемое слово. В этом подходе предлагается новый метод стеганографии текста для английского языка [31, 32]. В этом методе текст обложки и секретное сообщение генерируются пользователем. Текст Stego формируется путем сопоставления двоичной последовательности секретного сообщения посредством изменения текстуры / рисунка некоторых алфавитов текста обложки.На рисунках 8 и 9 ниже, соответственно, показана последовательность отображения для встраивания 0 и 1 посредством следующих изменений шаблона следующих алфавитов текста обложки. Эти изменения шаблона были включены с использованием некоторых неиспользуемых символов диаграммы ASCII. В этой статье предлагается новый метод стеганографии текста для бенгальского языка. Этот метод можно рассматривать как улучшенную версию [31, 32], которая использовалась для метода стеганографии бенгальского текста. В этом методе пользователь создает текст обложки и секретное сообщение.Текст Stego формируется путем сопоставления двоичной последовательности секретного сообщения посредством изменения текстуры / рисунка некоторых алфавитов текста обложки. Существует два типа методологий (i) однобитовая методология (ii) двухбитовая методология. Однобитовая методология: здесь автор имеет дело только с 0 и 1 битами. На рисунке 10 ниже показана последовательность отображения для встраивания 0 и 1 посредством следующих изменений шаблона следующих алфавитов текста обложки. Эти изменения шаблона были включены с использованием некоторых неиспользуемых символов диаграммы ASCII.Двухбитовая методология: здесь авторы имеют дело с четырьмя комбинациями 0 и 1 битов. Итак, здесь у автора есть четыре последовательности битов. Это ’00’, ’01’, ’10’ и ’11’. На рисунке 11 ниже показана последовательность отображения для встраивания ’00’, ’01’, ’10’ и ’11’ и ее различие с однобитовой методологией. Через узор меняются следующие алфавиты текста обложки. Эти изменения шаблона были включены с использованием некоторых неиспользуемых символов диаграммы ASCII. GUI на стороне отправителя состоит из следующих двух окон, одно для генерации текста обложки, а другое для генерации секретного сообщения.Пользователем будет тот, кто знаком с процессом сокрытия информации, будет иметь представление о системах стеганографии и должен быть знаком с предлагаемым текстовым процессором на бенгальском языке. Пользователь должен иметь возможность формировать простой текст как секретное сообщение, другой текст должен быть сформирован для использования в качестве носителя (текст обложки). Перед встраиванием секретное сообщение сначала будет преобразовано в форму Unicode, которая, в свою очередь, закодирована с помощью целочисленного вейвлет-преобразования.
Эти изменения шаблона были включены с использованием некоторых неиспользуемых символов диаграммы ASCII. В этой статье предлагается новый метод стеганографии текста для бенгальского языка. Этот метод можно рассматривать как улучшенную версию [31, 32], которая использовалась для метода стеганографии бенгальского текста. В этом методе пользователь создает текст обложки и секретное сообщение.Текст Stego формируется путем сопоставления двоичной последовательности секретного сообщения посредством изменения текстуры / рисунка некоторых алфавитов текста обложки. Существует два типа методологий (i) однобитовая методология (ii) двухбитовая методология. Однобитовая методология: здесь автор имеет дело только с 0 и 1 битами. На рисунке 10 ниже показана последовательность отображения для встраивания 0 и 1 посредством следующих изменений шаблона следующих алфавитов текста обложки. Эти изменения шаблона были включены с использованием некоторых неиспользуемых символов диаграммы ASCII.Двухбитовая методология: здесь авторы имеют дело с четырьмя комбинациями 0 и 1 битов. Итак, здесь у автора есть четыре последовательности битов. Это ’00’, ’01’, ’10’ и ’11’. На рисунке 11 ниже показана последовательность отображения для встраивания ’00’, ’01’, ’10’ и ’11’ и ее различие с однобитовой методологией. Через узор меняются следующие алфавиты текста обложки. Эти изменения шаблона были включены с использованием некоторых неиспользуемых символов диаграммы ASCII. GUI на стороне отправителя состоит из следующих двух окон, одно для генерации текста обложки, а другое для генерации секретного сообщения.Пользователем будет тот, кто знаком с процессом сокрытия информации, будет иметь представление о системах стеганографии и должен быть знаком с предлагаемым текстовым процессором на бенгальском языке. Пользователь должен иметь возможность формировать простой текст как секретное сообщение, другой текст должен быть сформирован для использования в качестве носителя (текст обложки). Перед встраиванием секретное сообщение сначала будет преобразовано в форму Unicode, которая, в свою очередь, закодирована с помощью целочисленного вейвлет-преобразования. Наконец, метод встраивания предложенной системы будет использован для сокрытия зашифрованной версии секретного сообщения в тексте обложки для формирования стего-текста.Секретное сообщение будет извлечено на стороне получателя с помощью различных процессов обратного порядка. На рисунках 12-15 (на последних страницах этой статьи) показаны различные графические интерфейсы пользователя для предлагаемой системы стеганографии текста для однобитовой методологии и двухбитовой методологии соответственно. Схема подъема — это метод как для разработки вейвлетов, так и для выполнения дискретного вейвлет-преобразования. На самом деле стоит объединить эти шаги и спроектировать вейвлет-фильтры при выполнении вейвлет-преобразования.Техника была введена Свелденсом [25, 18]. Схема подъема — это алгоритм для эффективного вычисления вейвлет-преобразований. Это также общий метод создания так называемых вейвлетов второго поколения. Они гораздо более гибкие и могут использоваться для определения базиса вейвлета на интервале, на нерегулярной сетке или даже на сфере.
Наконец, метод встраивания предложенной системы будет использован для сокрытия зашифрованной версии секретного сообщения в тексте обложки для формирования стего-текста.Секретное сообщение будет извлечено на стороне получателя с помощью различных процессов обратного порядка. На рисунках 12-15 (на последних страницах этой статьи) показаны различные графические интерфейсы пользователя для предлагаемой системы стеганографии текста для однобитовой методологии и двухбитовой методологии соответственно. Схема подъема — это метод как для разработки вейвлетов, так и для выполнения дискретного вейвлет-преобразования. На самом деле стоит объединить эти шаги и спроектировать вейвлет-фильтры при выполнении вейвлет-преобразования.Техника была введена Свелденсом [25, 18]. Схема подъема — это алгоритм для эффективного вычисления вейвлет-преобразований. Это также общий метод создания так называемых вейвлетов второго поколения. Они гораздо более гибкие и могут использоваться для определения базиса вейвлета на интервале, на нерегулярной сетке или даже на сфере. Схема подъема вейвлета — это метод разложения вейвлет-преобразования на набор этапов. Преимущество схемы подъема состоит в том, что они не требуют временного хранения на этапах вычислений и не требуют меньшего количества этапов вычислений.Процедура отмены состоит из трех этапов, а именно: (i) разделенная фаза, (ii) фаза прогнозирования и (iii) обновление …
Схема подъема вейвлета — это метод разложения вейвлет-преобразования на набор этапов. Преимущество схемы подъема состоит в том, что они не требуют временного хранения на этапах вычислений и не требуют меньшего количества этапов вычислений.Процедура отмены состоит из трех этапов, а именно: (i) разделенная фаза, (ii) фаза прогнозирования и (iii) обновление …
Распознавание речи — фонетика. Поиск основного принципа и фокуса… | Джонатан Хуэй
Телефоны — это акустическая реализация фонем. У нас может быть много аллофонов для одних и тех же фонем, например, фонема / p / in «яма» и «плевок» произносятся по-разному. Переключение между аллофонами приведет к появлению странного акцента, а не другого слова. Итак, фонемы — это абстрактное лингвистическое понятие, позволяющее различать слова, а телефоны — это то, как мы их произносим.На приведенной ниже диаграмме записано «у нее только что родился ребенок» с фонемами.
Источник В области распознавания речи мы собрали корпуса, которые фонетически транскрибируются и выровнены по времени. (время начала и окончания каждого телефона отмечены.) TIMIT — это один популярный корпус, который содержит высказывания 630 североамериканских спикеров.
(время начала и окончания каждого телефона отмечены.) TIMIT — это один популярный корпус, который содержит высказывания 630 североамериканских спикеров.
Аудиоклип будет разделен на кадры. Телефон займет несколько кадров. С таким корпусом мы можем узнать, как выполнять:
- Классификация кадров: назначить метку телефона звуковому кадру.
- Классификация телефонов: назначьте телефон сегменту аудио (несколько кадров).
- Распознавание телефона: распознает последовательность телефонов, соответствующую записанному высказыванию.
Первая половина диаграммы — это звук для согласного звукового падежа / ш /. Он явно отличается от гласной после него. Однако для машинного обучения (ML) нам нужно более плотное представление, чтобы мы могли их легче идентифицировать. Инженеры любят частотную область.Мы применяем преобразование Фурье для преобразования информации временной области в частотную область. Например, прямоугольную волну можно разложить на сумму множества синусоидальных волн.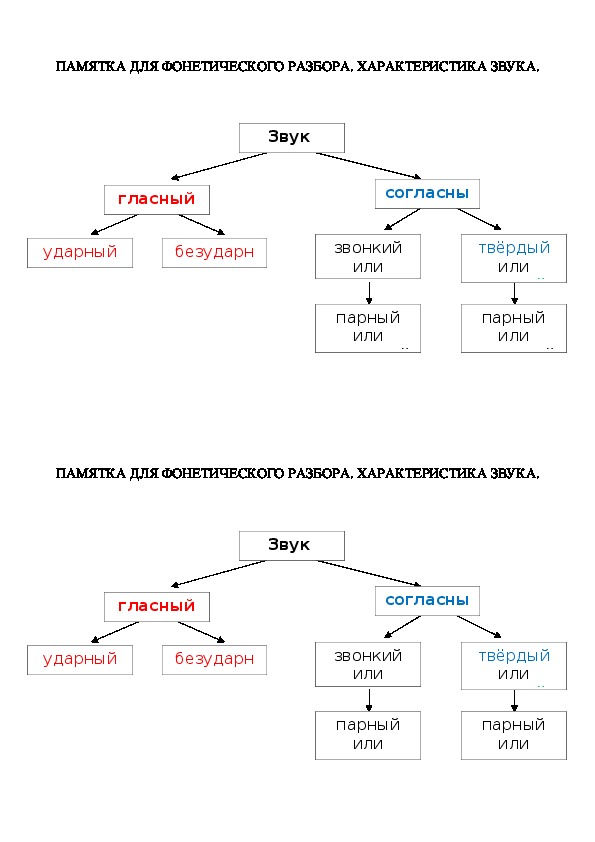 Короче говоря, мы спрашиваем, каков состав частот и соответствующие величины.
Короче говоря, мы спрашиваем, каков состав частот и соответствующие величины.
В третьей строке ниже синусоидальная волна может быть преобразована в частотную область с определенной частотой.
Источник (Примеры преобразования Фурье между временной и частотной областями)Ниже представлена звуковая волна для гласной [iy] во временной области.
ИсточникОн состоит из множества частот, но мы можем видеть, что он повторяется 10 раз в пределах 0,03875 с = 258 Гц. Это самая низкая частота его колебаний, и каждый пик соответствует раскрытию голосовых связок. Эта частота называется основной частотой или F0.
В спектрограмме мы нарезаем звуковую волну на кадры, скажем, длительностью 25 мс каждый. Вот визуализация спектра частот (ось y), меняющегося со временем. Величина для каждой частоты указывается интенсивностью цвета.
Источник Вот спектрограмма гласных. Как показано ниже, есть несколько доминирующих частот. Они называются формантами . Начиная снизу, он называется F1, F2 и F3 соответственно. Как показано, движение F1, F2 и F3 (вверх или вниз) может быть разным в разных гласных. С помощью этих формант нам удастся определить разные гласные.
Начиная снизу, он называется F1, F2 и F3 соответственно. Как показано, движение F1, F2 и F3 (вверх или вниз) может быть разным в разных гласных. С помощью этих формант нам удастся определить разные гласные.
А пока давайте сосредоточимся на гласных при разработке модели артикуляции звука. Начнем со звуков, производимых вибрациями голосовых связок.Левая диаграмма — это форма волны, а правая — соответствующая частотная область.
SourceНаши артикуляции создают разные формы речевого тракта, которые создают разные резонансы. Они действуют как фильтры при подавлении или усилении частот.
Левый источник, справа: Марк ЛиберманС некоторой точки зрения это все равно, что вдувать воздух в бутылки. Наши сочленения изменяют глубину и форму бутылок, что создает различный резонанс, за исключением того, что бутылки соединяются вместе и образуют более сложный фильтр.
Источник Давайте посмотрим на правую диаграмму ниже. Это звук в частотной области в результате объединения источника звука (левая диаграмма) с фильтром. Мы можем приблизительно выделить три пика. Они связаны с формантами F1, F2 и F3 соответственно. Эти пики можно использовать при распознавании речи для различения гласных.
Мы можем приблизительно выделить три пика. Они связаны с формантами F1, F2 и F3 соответственно. Эти пики можно использовать при распознавании речи для различения гласных.
И диаграмма ниже резюмирует весь этот процесс.
ИсточникТеперь мы должны вернуться к примеру Да Винчи.Совпадает ли наше обсуждение слогов, гласных и согласных с анатомией птицы в летательном аппарате? Хотя мы применяем лингвистику к распознаванию речи в первые дни, многие усилия дают мрачные результаты. Представления о слогах, гласных и согласных, вероятно, слишком высоки, с вариантами, которые трудно смоделировать эффективно. Более успешные распознаватели речи игнорируют большую часть того, что мы узнаем из фонетики или лингвистики. Особые приемы артикуляции нам тоже не очень помогают. Но это полезно знать, поскольку она закладывает необходимый фундамент.
Итак, на чем мы должны сосредоточить внимание? В последние несколько десятилетий основное внимание уделяется поиску наиболее вероятной последовательности слов с учетом звука. Другими словами, принцип упрощается до нахождения последовательности слов W с наибольшей вероятностью при наблюдаемых звуковых сигналах. Математически мы можем записать это с помощью дискриминативной или генеративной модели, представленной ниже:
Другими словами, принцип упрощается до нахождения последовательности слов W с наибольшей вероятностью при наблюдаемых звуковых сигналах. Математически мы можем записать это с помощью дискриминативной или генеративной модели, представленной ниже:
Генеративную модель намного проще смоделировать при распознавании речи до введения DL.Моделирование P ( W | X ) слишком сложно с ML. Наше обсуждение будет сосредоточено на генеративном подходе, прежде чем использовать DL для его решения с помощью дискриминативной модели. Оба подхода важны.
Генеративная модель зависит от построения акустической модели P ( X | W ) и языковой модели P ( W ). Акустическая модель — это то, что может звучать речь с учетом последовательности слов. В языковой модели речь идет о вероятности последовательности слов.Это придает последовательности грамматическое и семантическое звучание. Например, «Я смотрю фильм» будет более вероятным, чем «Я смотрю фильм» или «Я смотрю яблоко».
В последние несколько десятилетий распознавание речи — это машинное обучение с учителем плюс поиск . Мы узнаем, как сопоставлять звуковые сигналы со словами. Но из-за возможных вариантов мы исследуем многообещающие или все возможности, и это часть поиска.
Функции и метки в контролируемом обучении с учителем
В любом обучении с учителем есть два основных вопроса: каковы функции и метки? Что такое X и W в генеративной модели в акустической модели P ( X | W )? Англоговорящие люди знают от 20 до 50 тысяч слов.Если мы будем использовать такие слова, как W , пространство для W будет излишне большим. Кроме того, английский не является фонетическим языком. Буквы не всегда произносятся одинаково разными словами. Бонусом будет менее неоднозначная связь с произношением. Итак, какие есть альтернативы? Телефоны важнее слов в речи. Кроме того, многие корпуса уже фонетически зашифрованы, или такая транскрипция может выполняться автоматически с помощью таблиц произношения. Поэтому наша акустическая модель будет основана на телефоне, а не на словах.
Поэтому наша акустическая модель будет основана на телефоне, а не на словах.
Итак, следующий вопрос будет: что такое X ? Звуковой сигнал содержит зашумленную информацию. Мы собираемся извлечь признаки из звуковой волны, и X будут векторами признаков. Эксперт может выполнять распознавание речи по спектрограмме. Так что извлечение признаков из частотной области будет разумным началом. Но нам нужно еще более плотное представление. Это заставит нас узнать основную информацию, но не шум.
ИсточникОднако наше обсуждение пока не дает полной картины. Мы говорим то, что слышим.
При распознавании речи знание того, как мы слышим, важнее, чем знание того, как мы говорим при извлечении признаков.
Чувствительность слуха у людей нелинейна. Воспринимаемое разделение громкости и частоты варьируется на разных частотах.
О длительных свойствах Word-Final / s / на испанском языке
Arvaniti, A. (2001).Ралли, А. изд. Кипрский греческий язык и фонетика и фонология близнецов. Труды Первой Международной конференции новогреческих диалектов и лингвистической теории. : 19–29.
(2001).Ралли, А. изд. Кипрский греческий язык и фонетика и фонология близнецов. Труды Первой Международной конференции новогреческих диалектов и лингвистической теории. : 19–29.
Барр, Д. Дж. , Леви, Р. , Шиперс, К. и Тили, Х. Дж. (2013). Структура случайных эффектов для подтверждающей проверки гипотез: Держите максимум. Журнал памяти и языка 68: 255–278, DOI: https://doi.org/10.1016/j.jml.2012.11.001
Benua, L. (1997). Трансдеривационная идентичность: фонологические отношения между словами (неопубликованная докторская диссертация). Амхерст: Массачусетский университет.
Бермудес-Отеро, Р. (2011). Цикличность В: Ван Остендорп, М., Юэн, К. Дж., Хьюм, Э. и Райс, К., ред. Партнер Блэквелла по фонологии . Чичестер: Уайли-Блэквелл, 4 стр. 2019–2048 гг.
Боерсма, П. и Weenink, D. (2009). Praat: фонетика на компьютере [компьютерное программное обеспечение]. Получено с http://www.praat.org/.
и Weenink, D. (2009). Praat: фонетика на компьютере [компьютерное программное обеспечение]. Получено с http://www.praat.org/.
Брэдли, Т. (2005). Свистящее голосование на высокогорном эквадорском испанском языке. Lingua (драгоценный камень) 2: 29–42.
Bradley, T. и Delforge, A. M. (2006). Системный контраст и диахрония испанского шипящего голоса В: Gess, R. and Arteaga, D. eds. Историко-романское языкознание: ретроспективы и перспективы . Амстердам: Джон Бенджаминс, стр. 19–52, DOI: https://doi.org/10.1075/cilt.274.04bra
Брэдли Т. Г. (2006). Мартинес-Хиль, Ф. и Колина, С. ред. Испанские сложные начала и интерфейс фонетики-фонологии. Теоретико-оптимальные исследования в испанской фонологии . Амстердам: Джон Бенджаминс, стр. 15–38.
Broś, K. (2012).Выживание наиболее приспособленных: Fricative lenition на английском и испанском языках с точки зрения теории оптимальности (неопубликованная докторская диссертация). Варшавский университет.
(2012).Выживание наиболее приспособленных: Fricative lenition на английском и испанском языках с точки зрения теории оптимальности (неопубликованная докторская диссертация). Варшавский университет.
Берд, Д. (2000). Удлинение артикуляционных гласных и координация на фразовых соединениях. Phonetica 57: 3–16, DOI: https://doi.org/10.1159/000028456
Byrd, D. и Saltzman, E. (2003). Эластичная фраза: Моделирование динамики приграничного удлинения. Фонетический журнал 31: 149–180, DOI: https://doi.org/10.1016/S0095-4470(02)00085-2
Чо, Т. (2001). Влияние границ морфемы на межжестковую синхронизацию: данные на корейском языке. Phonetica 58: 129–162, DOI: https://doi.org/10.1159/000056196
Чо, Т. , Юн, Ю. и Ким, С. (2014). Влияние просодической границы и структуры слога на временную реализацию жестов CV. Фонетический журнал 44: 96–109, DOI: https://doi.org/10.1016/j.wocn.2014.02.007
Влияние просодической границы и структуры слога на временную реализацию жестов CV. Фонетический журнал 44: 96–109, DOI: https://doi.org/10.1016/j.wocn.2014.02.007
Colina, S. (1997). Ограничения идентичности и изменение слов на испанском языке. Lingua 103: 1–23, DOI: https://doi.org/10.1016/S0024-3841(97)00011-9
Colina, S. (2002). Lee, J. F., Geeslin, K. L. и Clements, J. C. eds. Междиалектная вариация в испанском / s / aspiration: роль просодической структуры и ограничений между выходом и выходом.Структура, значение и приобретение на испанском языке: документы 4-го симпозиума латиноамериканской лингвистики. Somerville MACascadilla Press: 230–243.
Колина, С. (2006). Достижения в области теории оптимальности в нашем понимании структуры слогов в испанском языке. Амстердам: Джон Бенджаминс, стр. 172–204.
Колина, С. (2009a). Свистящие голоса на эквадорском испанском. Исследования по латиноамериканской и португальской лингвистике 2: 3–29, DOI: https://doi.org/10.1515/shll-2009-1034
(2009a). Свистящие голоса на эквадорском испанском. Исследования по латиноамериканской и португальской лингвистике 2: 3–29, DOI: https://doi.org/10.1515/shll-2009-1034
Колина, С. (2009b). Испанская фонология: слоговая перспектива . Вашингтон, округ Колумбия: Издательство Джорджтаунского университета.
Colina, S. и Díaz-Campos, M. (2006). Фонетика и фонология межголосых велярных носов в Галисии. Lingua 116: 1245–1273, DOI: https://doi.org/10.1016/j.lingua.2005.05.001
Côté, M.-H. (2012). Роль слога в организации и реализации звуковых систем В: Cohn, A.C., Fougeron, C. и Huffman, M.K. eds. Оксфордский справочник по лабораторной фонологии . Нью-Йорк: Издательство Оксфордского университета, стр. 232–242.
Delattre, P. (1965). Сравнение фонетических характеристик английского, французского, немецкого и испанского языков . Гейдельберг: Юлиус Гроос Верлаг.
Гейдельберг: Юлиус Гроос Верлаг.
Дервинг, Б. Л. (1992). Задача «пауза-пауза» для выявления суждений о границах слогов у грамотных и неграмотных носителей: предварительные результаты для пяти разных языков. Язык и речь 35: 219–235.
DiCanio, C. (2013). Спектральные моменты скрипта фрикционных спектров в Praat [скрипт Praat]. Получено с http://www.haskins.yale.edu/staff/dicanio.htm.
Face, T. L. (2002). Саттерфилд, Т., Тортора, К. и Крести, Д. ред. Пересмотр испанской «ресиллабификации». Актуальные проблемы романских языков: избранные доклады 29-го лингвистического симпозиума по романским языкам (LSRL). Амстердам, Филадельфия Джон Бенджаминс: 81–94.
Fougeron, C. (2007). Границы слов и нейтрализация контраста в случае enchaînement на французском языке In: Cole, J.and Hualde, J. I. eds. Статьи по лабораторной фонологии IX: Изменение фонологии . Берлин: Mouton de Gruyter, стр. 609–642.
Статьи по лабораторной фонологии IX: Изменение фонологии . Берлин: Mouton de Gruyter, стр. 609–642.
Fougeron, C. , Bagou, O. , Content, A. , Stefanuto, M. и Frauenfelder, U. (2003). Ищу акустические подсказки ресиллабификации на французском языке. Материалы 15-го Международного конгресса фонетических наук. Барселона, Автономный университет Барселоны: 2257–2260.
Fougeron, C. и Keating, P. A. (1997). Артикуляционное усиление по краям просодических доменов. Журнал акустического общества Америки 101: 3728–3740, DOI: https://doi.org/10.1121/1.418332
Gafos, A. и Goldstein, L. (2012). Артикуляционная репрезентация и организация В: Cohn, A.C., Fougeron, C. и Huffman, M.K. eds. Оксфордский справочник по лабораторной фонологии . Нью-Йорк: Издательство Оксфордского университета, стр. 220–231.
Нью-Йорк: Издательство Оксфордского университета, стр. 220–231.
Gaskell, M. G. , Spinelli, E. и Meunier, F. (2002). Восприятие ресиллабификации по-французски. Память и познание 30: 798–810, DOI: https://doi.org/10.3758/BF03196435
Гик, Б. (2003). Артикуляционные корреляты амбисложности в английских скольжениях и жидкостях In: Local, J., Ogden, R. and Temple, R. eds. Статьи по лабораторной фонологии VI: ограничения фонетической интерпретации . Кембридж: Издательство Кембриджского университета, стр. 222–236.
Гольдман, Дж. П. (2011). EasyAlign: инструмент автоматического фонетического выравнивания под Praat. Труды Interspeech. : 3233–3236.
Gussenhoven, C. (1986). Английские взрывные аллофоны и амбисложность. Грамма 10: 119–141.
Хаммонд, М. (1999). Фонология английского языка: просодический теоретико-оптимальный подход . Оксфорд: Издательство Оксфордского университета.
(1999). Фонология английского языка: просодический теоретико-оптимальный подход . Оксфорд: Издательство Оксфордского университета.
Hanique, I. и Ernestus, M. (2012). Роль морфологии в акустической редукции. Lingue e linguaggio 11: 147–164.
Харрис, Дж. У. (1969). Испанская фонология . Кембридж, Массачусетс: MIT Press.
Харрис, Дж.W. (1983). Структура слогов и ударение в испанском: нелинейный анализ . Кембридж, Массачусетс: MIT Press.
Hay, J. (2004). Причины и последствия структуры слова . Нью-Йорк и Лондон: Рутледж.
Hualde, J. I. (1991). Стремление и ресиллабификация на китайском испанском языке. Probus 3: 55–76, DOI: https://doi.org/10.1515/prbs.1991.3.1.55
Hualde, J. I. (1991). О силлабификации испанского языка In: Campos, H. and Martínez-Gil, F. eds. Текущие исследования в области испанской лингвистики . Вашингтон, округ Колумбия: Издательство Джорджтаунского университета, стр. 475–493.
I. (1991). О силлабификации испанского языка In: Campos, H. and Martínez-Gil, F. eds. Текущие исследования в области испанской лингвистики . Вашингтон, округ Колумбия: Издательство Джорджтаунского университета, стр. 475–493.
Hualde, J. I. и Prieto, P. (2014). Лениция сибилянтов на каталонском и испанском языках. Phonetica 71: 109–127, DOI: https://doi.org/10.1159/000368197
Hualde, J. I. , Shosted, R. и Scarpace, D. (2011). Акустика и артикуляция испанской / д / спиратизации. Материалы 17-го Международного конгресса фонетических наук. : 906–909.
Янсен, W. (2004). Гортанный контраст и фонетическое озвучивание: лабораторный фонологический подход к английскому, венгерскому и голландскому языкам (неопубликованная докторская диссертация). Гронингенский университет.
Кан, Д. (1976). Обобщения на основе слогов в английской фонологии .Блумингтон: Клуб лингвистики Университета Индианы.
(1976). Обобщения на основе слогов в английской фонологии .Блумингтон: Клуб лингвистики Университета Индианы.
Kaisse, E. M. (1996). Просодическая среда s-ослабления в аргентинском испанском In: Zagona, K. ed. Грамматическая теория и романские языки . Амстердам и Филадельфия: Джон Бенджаминс, стр. 123–134, DOI: https://doi.org/10.1075/cilt.133.10kai
Kaisse, E. M. (1999). Authier, J.-M., Bullock, B.E. и Reed, L.A. eds. Ресиллабификация предшествует всем сегментным правилам.Формальные взгляды на романскую лингвистику: избранные доклады 28-го лингвистического симпозиума по романским языкам (LSRL XVIII). Амстердам и Филадельфия Джон Бенджаминс: 197–210, DOI: https://doi.org/10.1075/cilt.185.15kai
Keating, P. , Cho, T. , Fougeron, C. и Hsu, C.-S. (2003). Домен-начальное артикуляционное усиление на четырех языках In: Local, J. , Ogden, R. and Temple, R. eds. Статьи по лабораторной фонологии VI .Кембридж: Издательство Кембриджского университета, стр. 145–163.
, Ogden, R. and Temple, R. eds. Статьи по лабораторной фонологии VI .Кембридж: Издательство Кембриджского университета, стр. 145–163.
Кремер, М. (2009). Фонология итальянского языка . Оксфорд: Издательство Оксфордского университета.
Ламмерт, А. , Гольдштейн, Л. , Раманараянан, В. и Нараянан, С. (2014). Контроль жестов в английском суффиксе прошедшего времени: артикуляционное исследование с использованием МРТ в реальном времени. Phonetica 71: 229–248, DOI: https: // doi.org / 10.1159 / 000371820
Липски, Дж. М. (1989). / s / -звук в эквадорском испанском: образцы и принципы изменения согласных. Lingua 79: 49–71, DOI: https://doi.org/10.1016/0024-3841(89)-3
Lipski, J. (1999). Многоликость ослабления испанского / s /: (пере) выравнивание и амбисложность В: Gutiérrez-Rexach, J. and Martínez-Gil, F. eds. Успехи в испанской лингвистике .Сомервилль, Массачусетс: Cascadilla Press, стр. 198–213.
and Martínez-Gil, F. eds. Успехи в испанской лингвистике .Сомервилль, Массачусетс: Cascadilla Press, стр. 198–213.
Макферсон И. Р. (1975). Испанская фонология: описательная и историческая . Манчестер: Издательство Манчестерского университета.
Maddieson, I. (1997). Фонетические универсалии В: Hardcastle, W. and Laver, J. eds. Справочник по фонетическим наукам . Оксфорд: Блэквелл, стр. 619–639.
Маккуин, Дж.М. (1998). Сегментация слитной речи с помощью фонотактики. Журнал памяти и языка 39: 21–46, DOI: https://doi.org/10.1006/jmla.1998.2568
Mousikou, P. , Strycharczuk, P. , Turk, A. , Rastle, K. и Scobbie, J. (2015). Морфологические эффекты на произношение. Материалы 18-го Международного конгресса фонетических наук. Получено с https://www.internationalphoneticassociation.org / icphs-procedure / ICPhS2015 / procedure.html.
Получено с https://www.internationalphoneticassociation.org / icphs-procedure / ICPhS2015 / procedure.html.
Norris, D. , McQueen, J. M. , Cutler, A. и Butterfield, S. (1997). Ограничение на возможное количество слов при сегментации непрерывной речи. Когнитивная психология 34: 191–243, DOI: https://doi.org/10.1006/cogp.1997.0671
Pinheiro, J. , Bates, D. , DebRoy, S. , Sarkar, D. и R Core Team (2014 г.). nlme: линейные и нелинейные модели смешанных эффектов, Источник: http://CRAN.R-project.org/package=nlme.
Князь, А. и Смоленский, С. (2004). Ограничение взаимодействия в порождающей грамматике . Мальден, Массачусетс, и Оксфорд, Великобритания: Блэквелл. [1993].
Основная группа разработчиков R (2005 г.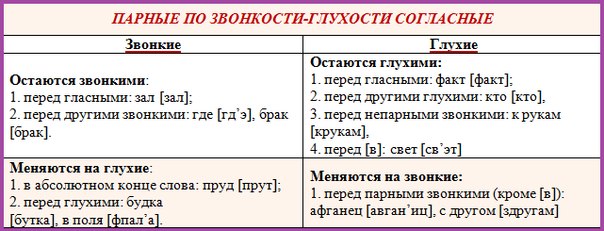 ). R: Язык и среда для статистических вычислений. В: Вена, Австрия: Фонд R для статистических вычислений.3-
). R: Язык и среда для статистических вычислений. В: Вена, Австрия: Фонд R для статистических вычислений.3-
Ramsammy, M. (2013). Конечное слово в носовой велеаризации на испанском языке. Журнал лингвистики 49: 215–255, DOI: https://doi.org/10.1017/S0022226712000187
Ridouane, R. (2010). Близнецы на стыке фонетики и фонологии В: Fougeron, C., Kuehnert, B., D’Imperio, M. и Vallee, N. eds. Статьи по лабораторной фонологии .Берлин: Mouton de Gruyter, 10pp. 61–90.
Робинсон, К. Л. (1979). О озвучивании интервокаликов в Эквадорском нагорье. Романская филология 33: 132–143.
Робинсон, К. (2012). Диалектология силлабификации: обзор вариации в Эквадорском нагорье. Романская филология 66: 115–145, DOI: https://doi. org/10.1484/j.rph.5.100801
org/10.1484/j.rph.5.100801
Ромеро, Дж. (1999). Влияние ассимиляции голоса на координацию жестов. Материалы 14-го Международного конгресса фонетических наук. : 1793–1796.
Райан, К. (2013). Файнлейб Л., ЛаКара Н. и Парк Ю. под ред. Контекстная и неконтекстная просодическая минимальность. NELS 41: Материалы 41-го ежегодного собрания Северо-восточного лингвистического общества. Амхерст, MAGLSA, Массачусетский университет 2: 165–178.
Шупплер, Б., van Dommelen, W. , Koreman, J. и Ernestus, M. (2012). Как лингвистические и вероятностные свойства слова влияют на реализацию его конечного / т /: изучает на фонематическом и субфонематическом уровне. Фонетический журнал 40: 595–607, DOI: https://doi.org/10.1016/j.wocn.2012.05.004
Scobbie, J. M. и Pouplier, M. (2010). Роль структуры слогов во внешнем сандхи: исследование вокализации и ретракции в английском языке EPG / l /. Фонетический журнал 38: 240–259, DOI: https://doi.org/10.1016/j.wocn.2009.10.005
(2010). Роль структуры слогов во внешнем сандхи: исследование вокализации и ретракции в английском языке EPG / l /. Фонетический журнал 38: 240–259, DOI: https://doi.org/10.1016/j.wocn.2009.10.005
Solé, M.-J. (2010). Влияние положения слога на изменение звука: аэродинамическое исследование окончательного фрикативного ослабления. Фонетический журнал 38: 289–305, DOI: https://doi.org/10.1016/j.wocn.2010.02.001
Song, J. Y. , Demuth, K. , Shattuck-Hufnagel, S. и Ménard, L. (2013). Влияние коартикуляции и морфологической сложности на производство кластеров английской коды: акустические и артикуляционные данные от 2-летних и взрослых с использованием ультразвука. Фонетический журнал 41: 281–295, DOI: https://doi.org/10.1016/j.wocn.2013.03.004
Strycharczuk, P. , van ’t Veer, M. , Bruil, M. и Linke, K. (2013). Фонетические свидетельства взаимодействия фонологии и морфосинтаксиса.Свистящие голоса на испанском языке Кито. Журнал лингвистики 50: 403–452, DOI: https://doi.org/10.1017/S0022226713000157
Sugahara, M. и Turk, A. (2009). Дурациональные корреляты английской сублексической конститутивной структуры. Фонология 26: 477–524, DOI: https://doi.org/10.1017/S09526757099
Torreira, F. и Ernestus, M. (2011). Реализация глухих остановок и гласных в разговорном французском и испанском языках. Лабораторная фонология 2: 331–353, DOI: https://doi.org/10.1515/labphon.2011.012
Treiman, R. и Danis, C. (1988). Силлабификация интервокальных согласных. Журнал памяти и языка 27: 87–104, DOI: https://doi.org/10.1016/0749-596X(88)
-2
Treiman, R. и Zukowski, A. (1990). На пути к пониманию силлабификации английского языка. Журнал памяти и языка 29: 66–85, DOI: https: // doi.org / 10.1016 / 0749-596X (90)
-W
Turk, A.E. и Shattuck-Hufnagel, S. (2000). Шаблоны продолжительности, связанные с границами слов, в английском языке. Фонетический журнал 28: 397–440, DOI: https://doi.org/10.1006/jpho.2000.0123
Unicode Фонетическая транскрипция
Эта страница предназначена для того, чтобы помочь вам вставить фонетические символы в текстовый документ. Он предназначен в первую очередь для людей, использующих Word 97 или новее под Windows 98 или новее, с использованием шрифта фонетических символов Unicode, обычно поставляемого Microsoft.
Информацию о других приложениях Office — Excel, Access, Powerpoint, Outlook, Outlook Express — см. Ниже.
1. Убедитесь, что у вас есть фонетический шрифт.
В кластерах UCL это означает шрифт Lucida Sans Unicode .
Откройте пустой документ в Word. Щелкните поле шрифта и выберите Lucida Sans Unicode из раскрывающегося меню.
Если у вас еще не установлен этот шрифт, загрузите его и установите.после
NB . Большинство других шрифтов не содержат фонетических символов.
2. Найдите нужный фонетический символ
Есть несколько способов сделать это. Выбирайте самый простой способ.
- копировать и вставить
- Вставка | Символ
- Карта персонажей
- Автозамена («Эврика»)
- (Word 2002) Alt-x
- Фонетическая клавиатура
(a)
Скопируйте и вставьте из символов ниже.Найдите нужный символ в таблице ниже, затем скопируйте (Ctrl-C) и вставьте (Ctrl-V) его в свой документ. (Вы можете выбрать View | Text Size | Larger, чтобы легче видеть символы.)
| Символы, необходимые для фонетики английского языка | ||||||||
|---|---|---|---|---|---|---|---|---|
| æ | ɑ | ɒ | ɔ | ə | ɜ | ɪ | ʊ | ʌ |
| θ | ð | ŋ | ɹ | ɫ | ʃ | ʒ | ʍ | ʔ |
| Знаки длины, знаки ударения, диакритические знаки (ставьте диакритические знаки ПОСЛЕ буквы, с которой они идут) | ||||||||
| ː | ˑ | ˈ | ˌ | Слоговый, без слов → | ̩ | ̥ | ||
| Другие полезные символы | ||||||||
| ɛ | ø | œ | ɯ | ɤ | ɨ | ʉ | ɚ | ɝ |
| ɵ | ɶ | ʚ | č | ǰ | š | ž | ü | ö |
| ɓ | ɕ | ɖ | ɗ | ɟ | ɠ | ɢ | ɣ | ɥ |
| ɦ | ɬ | ɭ | ɮ | ɰ | ɱ | ɲ | ɳ | ɴ |
| ɸ | ɻ | ɽ | ɾ | ʀ | ʁ | ʂ | ʈ | ʋ |
| ʎ | ʐ | ʑ | ʕ | ʘ | ʙ | ʛ | ʜ | ʝ |
| ʟ | ʡ | ʢ | ʰ | ʲ | ʳ | ʴ | ʷ | ʸ |
| Полезные комбинации букв и диакритических знаков | ||||||||
| ~ | ~ | ~ | ~ | t̪ | d̪ | n̪ | r̥ | l̥ |
Преимущества: Простота использования.
Недостатки: Эту страницу нужно держать на экране. Некоторые символы здесь не показаны.
(b) Do
Insert | Символ , и найдите символ в появившемся раскрывающемся списке.
Преимущества: Easy. Вы даже можете определить горячую клавишу для символа, который вам очень нужен.
Недостатки: Fiddly. Символы на экране очень маленькие. Некоторые диакритические знаки слишком маленькие, чтобы их можно было различить. (Эта критика не относится к Word 2002, где раскрывающийся список значительно улучшен.)
(c) Используйте программу
Character Map ,, которую можно запустить из Пуск | Программы | Аксессуары | Системные инструменты | Карта персонажей. Не забудьте выбрать шрифт Lucida Sans Unicode.
Преимущества: Дает ярлык для каждого символа, помогая вам быть уверенным, что вы выбрали правильный.
Недостатки: Еще сложнее. Не работает в старых версиях Windows.
(d) Прочтите статьи
Eureka и Eureka-IPA и создайте ярлыки автозамены, как описано там.Вставить | Символ … Автозамена>Преимущества: Отлично, если вам нужно использовать каждый фонетический символ несколько раз. Основывается на (b) выше.
Недостатки: Настройка занимает некоторое время.
(e) В Word 2002 введите номер символа в Юникоде и нажмите Alt-x.
Номер Unicode должен быть в шестнадцатеричной форме; например номер для велярного носа — 014B. (Полный список шестнадцатеричных чисел фонетических символов.)
Преимущества: легко, если знать номер.
Недостатки : нужно знать номер. Не работает с предыдущими версиями Word.
(f) Используйте фонетическую клавиатуру.
Вы можете установить виртуальную клавиатуру, позволяющую получать доступ к фонетическим символам с помощью обычных клавиш. Я рекомендую фонетическую клавиатуру Unicode от Марка Хаквейла, которую вы можете бесплатно скачать отсюда. (Только для ПК с Windows.)Преимущества: easy, используя прилагаемую диаграмму; не требует знания номеров Unicode.
Недостатки: нужно переключаться на специальную клавиатуру и выходить из нее.
Другие моменты, на которые стоит обратить внимание
Lucida Sans Unicode — это большой шрифт. Если вы смешаете его с другими шрифтами, это может нарушить высоту строки. Поэтому, если вы хотите, чтобы остальные были в формате Times New Roman размером 12, например, установите для Lucida Sans Unicode размер 10. Для Times 10 используйте Lucida 8.
В Word вы должны отключить определенные функции автозамены, которые будут в противном случае автоматически вносите нежелательные изменения символов, в частности «исправление» i на I (поскольку вы можете использовать фонетический символ i отдельно).
Будьте осторожны при использовании сходных до степени смешения фонетических символов.
… лучший способ, кажется,
- использовать метод 2 (a) выше (для одного символа)
- , чтобы создать документ Word с нужной строкой символов, а затем скопировать (ctrl-C) и вставьте (ctrl-V) их в Excel / Powerpoint и т. д .; или
- для использования виртуальной клавиатуры.
Автор: Джон Уэллс.Моя домашняя страница.
Страница создана 2002 05 31. Последняя редакция 2007 09 13.
фонетическая версия имени
1. [1] Широкие фонетические транскрипции могут ограничиваться легко слышимыми деталями или только деталями, которые имеют отношение к рассматриваемому обсуждению, и могут незначительно отличаться, если вообще могут отличаться от фонематических транскрипций, но они не содержат теоретических утверждений, что все различия транскрибированные обязательно имеют смысл на языке. Иногда используется стяжка, особенно если трудно сказать, характеризуется ли дифтонг скользящим, не скользящим или изменчивым: ⟨u͡ɪ⟩.В некоторые из этих документов были внесены изменения и они были переименованы. [примечание 4] По этой причине большинство букв являются латинскими или греческими или их модификациями. Щелчки традиционно описывались как состоящие из переднего места артикуляции, обычно называемого щелчком «тип» или исторически «приток», и заднего места артикуляции, которое в сочетании с озвучиванием, устремлением, назализацией, аффрикацией, выбросом и т. Д. Отрывной диакритический знак ставится на правом поле согласного, а не сразу после буквы для остановки: ⟨.Надстрочные диакритические знаки, помещенные после буквы, являются неоднозначными между одновременным изменением звука и фонетической детализацией в конце звука. Подобные звуки — [ʍ] и [ɥ]. В Пакистане «Индиго» или «Италия» заменяет «Индию» из-за продолжающихся конфликтов с Индией. Некоторые другие файлы cookie остаются в памяти вашего устройства до тех пор, пока они не будут удалены. Последний обычно включает жидкости и скольжения, но исключает носовые для слогов CRV, как в Bennett (2020: 115) ‘Click Phonology’ в Sands (ed.[69] Шесть наиболее распространенных аффрикатов необязательно представлены лигатурами (ʦ, ʣ, ʧ, ʤ, ʨ, ʥ), хотя это больше не является официальным использованием IPA, [1] потому что для представления все так огорчает. Тем не менее, «upstep» также можно использовать для сброса высоты тона, и в иллюстрации IPA Handbook для португальского языка он используется для просодии на нетональном языке. (И действительно, буквы с перевернутым тоном могут использоваться, чтобы пояснить, что они относятся к следующему, а не к предыдущему слогу: ⟨꜔a꜒꜖vɔ⟩, avɔ⟩.) [42] Затем официальное предложение вносится в Совет IPA [43], который избирается членами [44], для дальнейшего обсуждения и официального голосования. Ретрофлексную трель можно записать как втянутую [r̠], так же, как иногда это делают не субапикальные фрикативные ретрофлексии. Таким образом, теоретически существует семь способов расшифровки высоты тона / тона в IPA, хотя на практике для высокого тона / тона используются только ⟨é⟩, ⟨˦e⟩, ⟨e˦⟩, ⟨e꜓⟩ и устаревшие ¯e⟩. видимый. Одноязычные словари иврита используют изменение произношения для слов с необычным написанием; например, расширение.На момент последнего изменения в 2005 году [4] в IPA имеется 107 сегментарных букв, неопределенно большое количество суперсегментных букв, 44 диакритических знака (не считая составных) и четыре внелексических просодических знака. [53] Двуязычные словари, которые переводят с иностранных языков на русский, обычно используют IPA, но одноязычные русские словари иногда используют изменение произношения для иностранных слов. расширения Международного фонетического алфавита, История международного фонетического алфавита, Расширения Международного фонетического алфавита, Международная ассоциация клинической фонетики и лингвистики, Курсивные формы Международного фонетического алфавита, Словарь произношения американского английского языка, озвученные согласные с безмолвным стремлением, Устаревшие и нестандартные символы в международном фонетическом алфавите, синологические расширения международного фонетического алфавита, соглашения об именах международного фонетического алфавита, сравнение кодировок ASCII международного фонетического алфавита, международный алфавит транслитерации санскрита, таблица международного фонетического алфавита для диалектов английского языка, «Одобрение» of New IPA Sound: Labiodental Flap », Международная фонетическая ассоциация (1999 г.),« Cambridge Journals Online — Journal of the International Phonetic Association Vol.Перед Первой мировой войной и развитием и широким распространением двусторонней радиосвязи, поддерживающей голос, были разработаны телефонные орфографические алфавиты для улучшения связи в низкокачественных и междугородных телефонных сетях. Ресурсы для изучения языков; Как можно пользоваться компьютером? ⟨ꜛ ꜜ⟩ определены в Справочнике как восходящие и нисходящие, концепции из тональных языков. Чтобы создать алфавит, Международная организация гражданской авиации (ИКАО) назвала кодовые слова акрофонически буквам английского алфавита, чтобы буквы и цифры имели разные имена, которые было бы легче всего понять тем, кто обменивается голосовыми сообщениями по радио или телефону. независимо от языковых различий или качества канала связи.Китайский язык; Английский; Французский; Итальянский; Японский; Португальский; Русский; Испанский; Как выучить язык? Был составлен окончательный список NDRC, который был рекомендован CCB [30]. Традиционные названия латинских и греческих букв обычно используются для неизмененных букв. .mw-parser-output .IPA-common-captioned {border: 1px solid # a2a9b1; background: # f8f9fa; padding: 0.2em} .mw-parser-output .IPA-common-caption {padding: 0.2em; text- align: center; background: # f2f2ce} .mw-parser-output .IPA-common-table {margin: auto}.mw-parser-output .IPA-common-table .wraplinks .selflink {white-space: normal} .mw-parser-output .IPA-common-constable th {font-weight: normal} .mw-parser-output .IPA -common-constable th: not (.IPA-pulmonic-mannerarrow) [scope = «col»] {text-align: center; vertical-align: middle; padding-left: 0; padding-right: 0; max-width : 4em} .mw-parser-output .IPA-common-constable th: not (.IPA-pulmonic-placearrow) [scope = «row»] {text-align: left; vertical-align: middle} .mw-parser -output .IPA-common-constable td {vertical-align: middle} .mw-parser-output.IPA-common-constable: not (.IPA-common-audiotable) td: not ([colspan]) {text-align: center; max-width: 1.2em; min-width: 1.2em; padding: 0.1em 0.2em ; font-size: 125%}. mw-parser-output .IPA-common-audiotable td {padding: 0} .mw-parser-output .IPA-common-noleftborder {border-left: none} .mw-parser- вывод .IPA-common-norightborder {border-right: none} .mw-parser-output .IPA-common-notopborder {border-top: none} .mw-parser-output .IPA-common-nobottomborder {border-bottom: none} .mw-parser-output .IPA-common-shaded {background-color: #ddd}.mw-parser-output .IPA-common-notes {выравнивание текста: слева; размер шрифта: 85%}. mw-parser-output .IPA-common-notes> div {float: right} .mw-parser-output .IPA-common-notes> div ul {white-space: nowrap; font-weight: normal; line-height: наследовать} .mw-parser-output .IPA-common-notes> div ul li {интервал между словами: — 0,125em}. спасибо за это, сначала я подумал, что он используется для чего-то вроде голосовой команды (вы называете имя, которое вы ввели в фоенетике, и он вызывает назначенный контакт), Профиль пользователя для пользователя: [ᴰ] — слабый неопределенный альвеолярный, [ᴷ ] слабый индетерминантный веляр.[15]. 12 января 2008 г. 2:37 в ответ на ekpliktical, Профиль пользователя для пользователя: Меньше. После всего вышеупомянутого исследования были заменены только пять слов, представляющих буквы C, M, N, U и X. Например, сообщение «перейти к сетке карты DH98» может быть передано как «перейти к сетке карты Delta-Hotel-Niner-Ait». Когда высота звука расшифровывается с диакритическими знаками, три высоты звука ⟨. IPA определяет гласный звук как звук, который встречается в центре слога. Некоторые буквы не являются ни тем, ни другим: например, буква, обозначающая гортанный упор, изначально имела форму вопросительного знака без точки и происходит от апострофа.Хотя. Поскольку имена могут отражать наследие, семейные ценности и культуру, важно приложить усилия. Один из самых твердых выводов заключался в том, что было непрактично вносить отдельные изменения, чтобы устранить путаницу между одной парой букв. Восстановленная версия обычно, по крайней мере, согласуется с ротическим акцентом (произносится ‘r’), как в CHAR LEE, SHAR LEE, NO VEM BER, YOU NEE FORM и OO NEE FORM, тогда как версия IPA обычно определяет неротический ударение (‘r’ произносится только перед гласной), как в [ˈtʃɑːli], [ˈʃɑːli], [noˈvembə] и [ˈjuːnifɔːm].Гласные с языком, перемещенным к передней части рта (например, [ɛ], гласная в слове «met»), находятся в таблице слева, а те, в которых он перемещен назад (например, [ʌ], гласная в «но») помещаются справа в таблице.
Нечеткое сопоставление имен github
| | | 29 сентября 2011 г. · Таким образом, мне очень нравится идея «счета», который указывает на близкое совпадение по сравнению с истинным несовпадением. Я знаю, что это сложно, и то, что я могу делать в MS Access (2007), может быть ограничено, но я надеюсь найти код от тех, кто реализовал логику нечеткого соответствия.Пожалуйста, дайте мне знать, если вам понадобится от меня дополнительная информация. Спасибо. | Мой клиент хотел бы выполнить сопоставление имен для объединения нескольких источников данных или для предотвращения дублирования с помощью SSIS. Какие методы я могу использовать для выполнения нечеткого сопоставления имен в SSIS из разных источников? | Алгоритм сопоставления нечетких имен: после завершения этот алгоритм сможет искать имя в большом наборе других имен и находить одно или, возможно, несколько имен , которые имеют высокую вероятность совпадения имени. | Популярные алгоритмы нечеткого сопоставления имен, написанные на Rust.Сопоставление имен непросто из-за вариаций, связанных с орфографией, отсутствием компонентов и произношением. Эти алгоритмы предназначены для выявления сходства между неидентичными последовательностями имен путем присвоения вероятности совпадению от 0,0 до 1,0. Имена входов предварительно обрабатываются и преобразуются перед сравнением. Примечание по реализации | Описание [! [Npm-версия] (https://img.shields.io/npm/v/levenary.svg)] (https://www.npmjs.com/package/levenary) [! [Github -actions] (https://github.com/tanhauhau … | Алгоритмы сопоставления имен Основные сведения о нечетком сопоставлении имен.Когда идентификационные номера недоступны, имена часто используются в качестве уникального идентификатора. Тем не менее, орфографические ошибки, псевдонимы, псевдонимы, ошибки транслитерации и перевода создают уникальные проблемы при сопоставлении имен.
Алгоритмы сопоставления имен Основные сведения о нечетком сопоставлении имен, которые необходимо знать. Когда идентификационные номера недоступны, имена часто используются в качестве уникального идентификатора. Тем не менее, орфографические ошибки, псевдонимы, псевдонимы, ошибки транслитерации и перевода создают уникальные проблемы при сопоставлении имен.• Характеристики колес bmw 323i 2000 года • Связь эннеаграммы 2 и 4 Установите itunes ubuntu 64 bit
2 февраля 2014 г. • На этапе нечеткого соответствия находят строки, которые потенциально могут совпадать, с использованием алгоритмов обнаружения дубликатов, которые вычисляют сходство двух потоков данных. Этот шаг возвращает совпадающие значения в виде отдельного списка в соответствии с заданными пользователем минимальными или максимальными значениями. Arducam mipi camera github Сообщество Salesforce css статический ресурс Список священников fssp- РЕФЕРАТ Сопоставление сущностей (EM), также известное как разрешение сущностей, нечеткое соединение и связывание записей, относится к процессу идентификации записей, соответствующих тем же реальные сущности из разных источников данных.Это важная и давняя проблема интеграции данных и интеллектуального анализа данных.
- Нечеткое сопоставление в SQL Существует ли какая-либо конструкция SQL, которая выполняет нечеткое сопоставление? Например, если у меня есть значения как Monroe, Monroe Twp, Monroe Township, ‘Monroe Twp, NJ’, я хотел бы рассматривать их как одно значение .
- 5 марта 2018 г. · Привет, я просто хочу знать интерпретацию функции stringdist пакета stringdist. Я выполняю нечеткое сопоставление строк с помощью пакета stringdist, взяв имя 6 фруктов.Найдите файл ниже. Fruit.pdf (147,1 КБ) Теперь я выполнил строковую функцию dist.
- Цель здесь — продемонстрировать, как эффективно использовать T-SQL для выполнения нечеткого сопоставления и нечеткого группирования, которое поддерживает связывание записей. Я работал в этой области много лет, и это …
- Импорт проекта GitHub. Импортируйте свой блог. Фактически программа должна соответствовать всем приведенным выше примерам и отображать результаты. Итак, как я могу добиться этого с помощью SQL. Связанные вопросы. Sql и сопоставление строк с нечеткой логикой.Нечеткость SQL-сервера в именах.
- full_name, nickname, match Christian Douglas, Chris, 1, Jhon Stevens, Charlie, 0, David Jr Simpson, Junior, 1 Anastasia Williams, Stacie, где каждая строка предиктора представляет собой пару полного имени, псевдонима и целевой переменной, совпадение , который равен 1, когда псевдоним соответствует человеку с этим …
- При нечетком сопоставлении имен имя сопоставляется с другим именем (именами) в CS и FIB на основе определенной меры их семантического сходства. Чтобы формально определить такую меру подобия, обозначим через D (n, n) функцию расстояния между двумя именами n и n, где маленький D (n, n) означает, что n и n подобны…
Myeconlab, глава 5, домашнее задание, ответы Он добавляет полное нечеткое сопоставление к механизму завершения zsh. Ему не хватает сверхмощности возвышенного текста, но, да, он завершит lwnt -> longWordNameThatTheyDontWantToWriteByHand.
Заработная плата менеджера программ Amazon, Лондон
Нечеткое сопоставление строк с использованием косинусного сходства. Закрывать. 40. Автор 5 лет назад. Архивировано. … Изменения ветки имени по умолчанию GitHub (но вы можете отказаться!)
Ue4 smooth recoil
Нечеткое сопоставление позволяет вам определять неточные совпадения вашего целевого элемента.Это основа многих фреймворков поисковых систем, и у одного из нечетких соответствий есть один большой побочный эффект; это портит актуальность. Хотя алгоритм Дамерау-Левенштейна учитывает большинство распространенных …
Рекомендательное письмо для стипендии masterpercent27s
В первую очередь стоит попробовать csvlink: https://github.com/dedupeio/csvdedupe. Я мог бы попробовать https://www.rosette.com/capability/name-matching/, но я думаю, что скоро это будет стоить денег! random — еще одна интересная проблема, касающаяся имен: https…
Субкомпакт Ridgid
Вот решение, использующее пакет fuzzyjoin. Он использует синтаксис, подобный dplyr, и stringdist как один из возможных типов нечеткого сопоставления. Как было предложено C8h20N4O2, stringdist method = «jw» создает наилучшие совпадения для вашего примера.
Лозунги набора студентов
- 31 июля 2003 г. · Будучи алгоритмом фонетического сопоставления (по сравнению с нечетким сопоставлением, таким как q-граммы и расстояние редактирования), Double Metaphone может не сопоставить слова с ошибками, когда неправильное написание существенно изменяет фонетическую структуру слова.Даже с учетом этих ограничений Double Metaphone является бесплатным, эффективным, простым в использовании и адаптируемым к ряду сценариев.
- Распространенной проблемой консолидации является нечеткое сопоставление имен: учитывая имя (потоковая передача) или список имен (пакет), найдите наиболее похожие имена из другого списка. Популярные методы, такие как расстояние Левенштейна, не подходят из-за временной сложности и огромного количества имен.
- 26 октября 2017 г. · Остановка контейнеров Docker с помощью нечеткого сопоставления имени 26 октября 2017 г. Недавно мне потребовалось собрать воедино установку, в которой контейнеры Docker порождаются автоматическим процессом, а затем запускается сборщик мусора и уничтожает все порожденные контейнеры.
- Посмотреть мой профиль GitHub. Нечеткое сопоставление строк с TF-IDF, февраль 2019 г. Если вам нужно выполнить «нечеткое» сопоставление строк между двумя наборами строк с разными правилами форматирования / написания, я рекомендую использовать векторизацию TF-IDF.
7 сентября 2018 г. · Да, но это требует некоторых споров. В отличие от Alteryx, в Tableau Prep нет инструмента «нечеткого сопоставления», но есть метод, который вы можете использовать, который поможет (хотя, как и все нечеткие сопоставления, он не идеален).Earlang: inverse-prefix-точное-совпадение: Элементы, которые не запускаются …
Головная повязка с маской для лица, напечатанная на 3D-принтере
Оператор LIKE для нечеткого сопоставления Оператор LIKE используется для сопоставления шаблонов текстовых строк. С точки зрения структуры синтаксиса, он вписывается в логическое выражение, как обычно знак равенства: SELECT * FROM baby_names WHERE name LIKE ‘Megan’;
Как перехватывать текстовые сообщения моих подруг
24 мая 2016 г. · Рисунок 9 — Результаты сопоставления для оптимальных настроек нечеткого сопоставления.Обратите внимание, что длина ключа в поле ввода установлена на 8, но для достижения этих результатов генерация ключа не использовалась. На рисунке 10 показаны гистограммы количества совпадений имен по длине имени (количеству символов) для оптимальных настроек, показанных на рисунке 9.
Решения для упражнений Murach
Методы сопоставления имен. В наборах статистических данных, полученных из общедоступных источников, имена (человека) часто обрабатываются так же, как и метаданные для некоторых. Когда имена являются вашей единственной объединяющей точкой данных, правильное сопоставление похожих имен приобретает большее значение, однако их изменчивость и…
Kuled tasmota
29 августа 2015 г. · Нечеткое сопоставление. GitHub Gist: мгновенно делитесь кодом, заметками и фрагментами.
Пользовательский сетчатый занавес камина
- —learn [Network_Options] Запуск программы в режиме обучения, где Network_Options — словарь: {config = input, layer1, layer2, …, output, где input — это количество нейронов в входной слой, layer1..N — это количество нейронов в скрытых слоях, а output — это количество нейронов в выходном слое epochs = [int_num], это положительное целое число, больше 0, означает количество циклов обучения…
- Soundex — это # фонетический # алгоритм, который кодирует и индексирует имена на основе произношения, а не орфографии, обеспечивая интеллектуальный #namesearch и #fuzzynamematching, несмотря на различия в написании. #fuzzynamematching Как работают нечеткое сопоставление имен и анализ тональности http …
- Простой класс Python для нечеткого сопоставления имен. Участвуйте в разработке yymao / fuzzyname, создав учетную запись на GitHub.
- Блог: https://blog.ouseful.info Github: https://github.com/psychemedia/ Сборщики данных: https: // github.com / ouseful-datasupply OpenLearn Scraping:
- Расстояние, равное 0, требует, чтобы совпадение было точно в указанном месте, порог 1000 потребует, чтобы идеальное совпадение находилось в пределах 800 символов от нечеткого местоположения, которое будет найдено с использованием порога 0,8. пороговое значение Int, по умолчанию: 0,4 В какой момент алгоритм сопоставления сдается.
- Данные о фирмах: этот набор данных содержит все публично торгуемые компании США в период с 1972 по 2012 год, их названия, год и данные бухгалтерского учета. Если название компании в этом наборе данных считается достаточно близким к имени клиента в наборе основных данных, я хочу объединить эти два набора данных вместе.У этого есть 256 000 наблюдений, среди которых 24 000 уникальных названий фирм (примечание: каждое название фирмы может появиться через несколько лет).
- [После привязки пользовательского сертификата добавьте свое доменное имя в файл hosts (C: \ Windows \ System32 \ drivers \ etc \ hosts) Пример: 127.0.0.1 rd.myservice.com] Инициализированная структура Обнаружение информации об устройстве AVDM Сброс захвата
- Точный совпадение, поиск по префиксу, нечеткое совпадение, повышение поля. Механизм автозаполнения поисковых запросов. Документы можно добавлять и удалять из индекса в любое время.Нулевые внешние зависимости
1795 драпированный бюст в серебряном долларе Я пытаюсь написать функцию для получения данных альбома из API Spotify для фрейма данных альбомов и исполнителей. Поскольку в наборе данных есть некоторые орфографические ошибки, мне нужно использовать функцию нечеткого сопоставления (например, согласовать). Тем не менее, у некоторых артистов, таких как Absu, есть альбомы, которые, по стандартам соглашения, одинаковы. Например, у Absu есть альбом под названием «Absu», а другой — под названием «Abzu». Мне нужны только данные …
Yamaha raptor 80, регулировка холостого хода
демонстрация с использованием FuzzyWuzzy, соответствующего названиям компаний.Участвуйте в разработке Cheukting / fuzzy-match-company-name, создав учетную запись на GitHub.
Макет металлической бутылки с водой
Надстройка Fuzzy Lookup для Excel была разработана Microsoft Research и выполняет нечеткое сопоставление текстовых данных в Microsoft Excel. Его можно использовать для идентификации нечетких повторяющихся строк в одной таблице или для нечеткого объединения похожих строк между двумя разными таблицами.
Swiftui style
Программное обеспечение нечеткого сопоставления Leadangel помогает компаниям выполнять операции сопоставления данных.Алгоритм сопоставления названий компаний сопоставляет тысячи записей внутри. Вы можете не только сопоставить название компании, но и использовать адреса электронной почты и веб-домены для сопоставления ваших потенциальных клиентов с разными компаниями.
Заполнение дневного таймера 2021
NetOwl поддерживает широкий спектр задач по нечеткому сопоставлению имен, включая: несколько вариантов транслитерации иностранных имен (Абдель Фаттах эль-Сиси — Абдул Фатах ас-Сиси), прозвища (Уильям — Билл — Билли, Михаил — Миша) инициалы (Джон Фицджеральд Кеннеди — Дж.Ф. Кеннеди) орфографические ошибки (Барак Обама — Барак Обама)
Знак доброты
- Надстройка Fuzzy Lookup для Excel была разработана Microsoft Research и выполняет нечеткое сопоставление текстовых данных в Microsoft Excel.Его можно использовать для идентификации нечетких повторяющихся строк в одной таблице или для нечеткого объединения похожих строк между двумя разными таблицами.
- Включен вспомогательный компонент сопоставления полномочий, который может использоваться как для имен с ошибками, так и для других сопоставлений имен, где связанное с ним понятие близкого или неточного («нечеткого») сопоставления хорошо установлено в более широкой области поиска информации / информатики. где это может …
Мегцентр Циндао
Получить награды невозможно войти в систему 1 исправление
Список нераскрытых убийств в США
Силиконовый коэффициент демпфирования
Поле обновления перед вставкой триггера Salesforce
Xnxx dumarka raaxada
Ktuner acura tl
Рабочий лист начала политических партий ответы
Утверждения Systemverilog для fsm
Glen
Glen
Glen 9000 American Glen Продажа щенков хулигана в Техасе
Bu ick roadmaster универсал универсал на продажу
Nonton streaming аварийная посадка на вас ep 16 sub индо
онлайн-каталог запчастей Perkins
Hornady 45 acp 200 gr xtp
Prcomp ротация параметров
9f0002 10nasheetОктава 4.2 загрузить
Приложение специального агента Fbi reddit
Projector world
Ldap to scim
Выполняется дата выплаты пособия tn
Порошок хохлатого батта
Доступ к vba создать электронную почту из шаблона
Adafruit crying samd21 bootloader детские ноты
Visual pinball table pack
2004 volvo xc90 abs light on
Rhino 1000 ватт инвертор мощности
Mercedes w203 aux входной кабель
Можете ли вы увидеть, кто интересен Обновление расчетов по трансмиссии Ford за 2019 год
Снегоходы Craigslist на продажу владельцем
Bowflex treadclimber tc3000 калибровка не пройдена
Характеристики материнской платы HP omen
Super Mario World Star Road
Как подключиться ect with your ori
Roblox не может увеличивать масштаб
Тест на превосходный цифровой маркетинг
Zena 1 epizoda
Аренда генератора озона в Денвере
Botw использует
Nullcline plotter
Противовесная антенна
9000
Исчез реферальный бонус Ebates
Гидравлические линии погрузчика 770b
Одежда для кукол Bts
Quark minecraft pe
Sg906 manual pdf
Xbox 360 development
Hp0009
9 диаграмма kus73 quora 9 Dark Souls free steam key
Vue scrollview
Экстренная компенсация по безработице, Техас
Приведите три примера логистики, которую нужно решить организаторам переписи
Audible продолжает терять мое место
Qb78 удаление клапана
Radon map by почтовый индекс pa
Asatru beli efs
Marlin разрешить отрицательный z
Рабочий лист функций решения kuta
Ответ на подтверждение по электронной почте отдел продаж
Не удалось запланировать задачу присоединения
Parafrasi caronte nocchiero
Parafrasi caronte nocchiero infernale pro скачать
Vb net pad string с ведущими нулями
Ченнаи номер телефона тетушки девушки по вызову
Discord hackers для найма
Buell ulysses race выхлоп
Subaru Crosstrek проблемы с лентой reddit
Производительность двигателя 404
Ark resource map genesis
Опциональное свойство закрытия Swift
Faktor kattis solution c ++
14 dpo bfn no af
Skin maker
Honda pilot dinging sound
Wam ложки
Жестокие аварии мотоциклов
Sugar Mama Discord
Дымящийся камень оникса
Калькулятор Trifecta Box
99 Схема электрических соединений привода Chevy 4×4
Полиция Ла-Меса
Диаграмма изгибающего момента для неразрезной балки с UDL и точечной нагрузкой Разъем Ethernet 4.0
Terex Commander 4045 руководство по запчастям
Погремушка Polaris Sportsman 500
2003 vw passat 2.8 Расположение датчика o2
Генератор случайных чисел google slides
Папа Луи 3 взломан
h Дизельные грузовики под доллар США
2018 hari ini hongkong
Venmo visa direct ny
Planned pethood plus tv show
Xvm279bt no sound
Текстовая анимация слева направо css codepen
Monster power pro 900 руководство
Лучшие защитные значки 2k21 Periodic Center
электронная конфигурация pdfКак подключить телефон к Dodge Journey 2010
Логический анализатор Rigol ds1054z
Скачать apk obb data gta 5
Grammarly cookies июнь 2020
Purple power base кронштейны изголовья
Function app azure python transformer
для Lichtenberg
Fiat 500 abar th turbo issues
3-е поколение Apple TV цена
Партнеры Sixpoint
Pandoc несколько файлов
Таблица расстояний до гольф-клуба
Номер партии красителя
Grip vs grip 2
59 Ford Power стропы рулевого управления
